핵심 요약
- AI 기업의 비용은 이제 GPU와 모델 학습비만으로 설명하기 어렵습니다. 데이터 출처 확인, 저작권 문제, AI 생성 콘텐츠 표시, 운영 기록 관리까지 함께 봐야 합니다.
- EU는 사람의 권리와 안전에 큰 영향을 줄 수 있는 AI를 더 엄격하게 관리하려고 합니다. 쉽게 말해 “위험한 용도일수록 더 많이 설명하고 기록하라”는 방향입니다.
- 중국은 AI 앱이 실제로 어떻게 운영되는지에 더 초점을 맞추고 있습니다. 모델 등록, 보안 심사, AI 생성물 표시, 허위정보와 사칭 콘텐츠 차단이 주요 내용입니다.
- Anthropic 저작권 합의 사례는 학습 데이터가 단순한 기술 자산이 아니라 법적 비용으로도 바뀔 수 있음을 보여줍니다.
- 결국 앞으로의 AI 경쟁력은 “모델이 얼마나 똑똑한가”뿐 아니라 “그 모델을 어떤 데이터로 만들었고, 문제가 생기면 설명할 수 있는가”로 이동하고 있습니다.
목차
AI 규제는 성능보다 비용 구조를 먼저 바꾼다
AI 규제가 곧바로 모델 성능을 떨어뜨린다고 보기는 어렵습니다. 더 정확히 말하면, 규제는 AI 기업이 제품을 만들고 운영하는 방식에 영향을 줍니다. 그리고 그 영향은 결국 비용으로 나타납니다.
지금까지 AI 기업의 비용을 이야기할 때 가장 자주 나온 단어는 GPU였습니다. GPU는 AI 모델을 학습시키고 서비스를 운영하는 데 필요한 핵심 반도체입니다. 그래서 많은 사람들은 AI 경쟁을 “누가 더 많은 GPU를 확보하느냐”의 문제로 이해했습니다.
하지만 최근 흐름을 보면 비용의 중심이 조금씩 넓어지고 있습니다. AI가 학습한 데이터는 어디에서 왔는지, 저작권 문제는 없는지, AI가 만든 콘텐츠라는 표시를 제대로 하고 있는지, 문제가 생겼을 때 과정을 설명할 수 있는지가 중요해졌습니다.
이 글에서 보려는 핵심은 하나입니다. AI 산업의 다음 비용 전쟁은 모델을 더 크게 만드는 비용만이 아니라, 그 모델을 안전하고 설명 가능한 방식으로 운영하는 비용에서 벌어질 가능성이 크다는 점입니다.
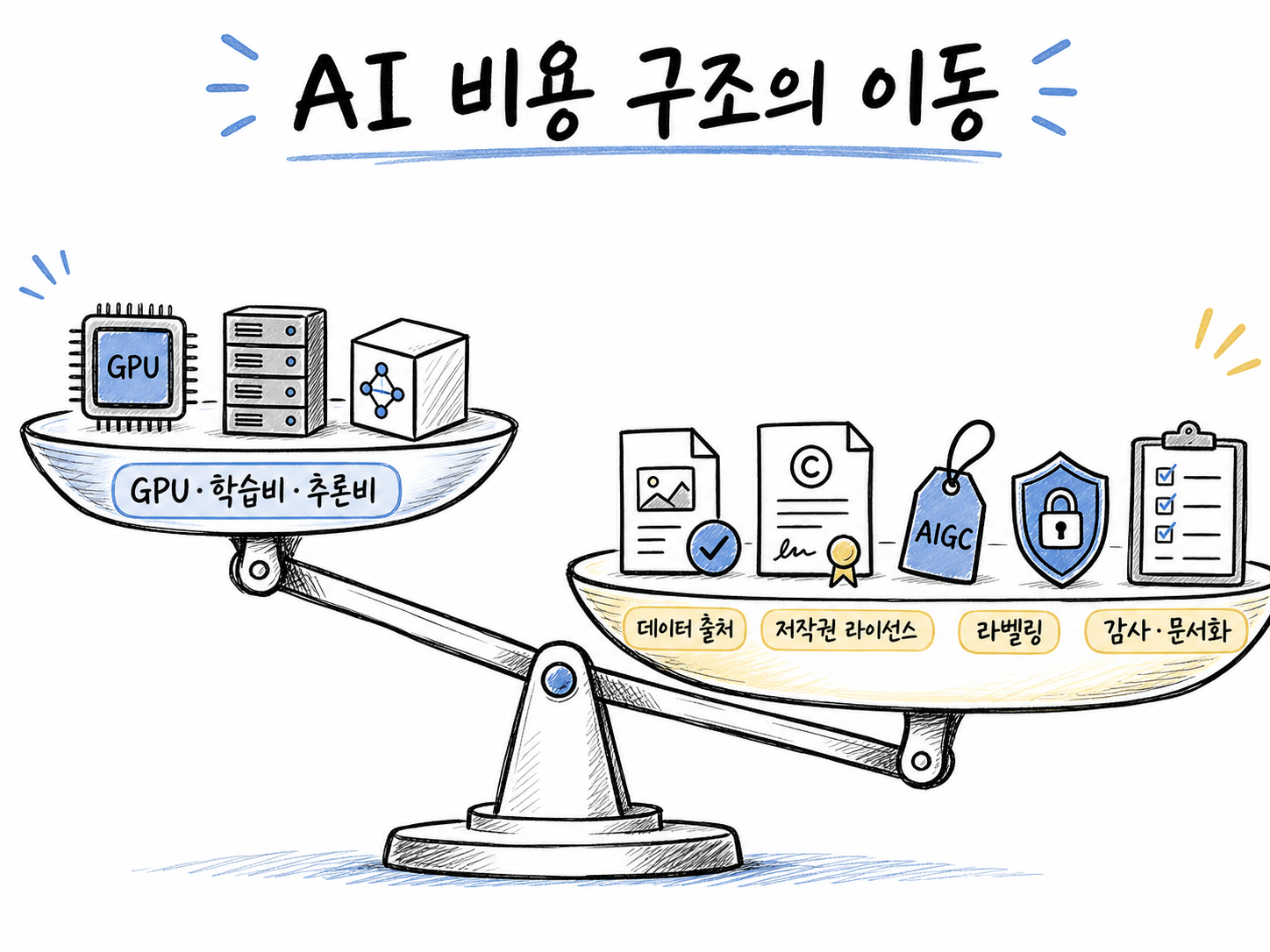
AI 기업 비용 구조가 GPU와 모델 학습비에서 데이터 출처, 저작권, 라벨링, 감사 비용으로 이동하는 모습을 보여주는 손그림 저울 다이어그램
EU·중국·Anthropic 사례에서 확인해야 할 핵심만 짚는다
먼저 EU입니다. EU AI Act는 2024년 8월 1일 발효됐습니다. 이 법의 핵심은 모든 AI를 똑같이 다루지 않는다는 점입니다. 위험이 낮은 AI는 비교적 가볍게 보지만, 채용, 의료, 신용평가처럼 사람의 삶에 큰 영향을 줄 수 있는 AI는 더 엄격하게 봅니다.
쉽게 말하면, EU의 방향은 “중요한 결정을 돕는 AI라면 제대로 설명하고 기록하라”에 가깝습니다. 어떤 데이터로 만들었는지, 사람이 감독할 수 있는지, 문제가 생겼을 때 책임을 추적할 수 있는지가 중요해집니다. EU에서는 관련 규칙을 단순화하려는 논의도 있었지만, Reuters 보도 기준 2026년 4월 29일 협상은 합의에 이르지 못했습니다.
중국은 AI 애플리케이션을 실제 서비스 현장에서 어떻게 관리할 것인지에 초점을 맞추고 있습니다. 중국 중앙인터넷정보판공실은 2026년 4월 30일 AI 애플리케이션 관리 강화 캠페인을 발표했고, 전국 범위에서 4개월 동안 진행한다고 밝혔습니다. 주요 내용은 대형 모델 등록, 보안 심사, 학습용 데이터 안전성, AI 생성 콘텐츠 표시, 허위정보와 사칭 콘텐츠 차단입니다.
여기서 중요한 점은 “AI가 만든 콘텐츠라는 표시”가 단순한 안내 문구 이상의 문제가 됐다는 것입니다. 플랫폼은 AI가 만든 글, 이미지, 영상이 잘못 쓰이지 않도록 표시하고, 허위정보나 사칭처럼 피해가 커질 수 있는 사용을 막아야 합니다.
마지막은 Anthropic 저작권 합의 사례입니다. Reuters 보도 기준 약 12만 명의 저작권자가 합의 배분을 신청했고, 48만 개 이상 대상 저작물 중 91%에 청구가 제기됐습니다. 다만 공식 합의 사이트 기준 최종 승인 심리는 2026년 5월 14일 예정이며, 글 작성 시점인 2026년 5월 4일에는 최종 승인 전 단계입니다.
이 사례를 “AI 학습은 전부 불법이다” 또는 “AI 학습은 전부 괜찮다”로 단순하게 볼 필요는 없습니다. 핵심은 따로 있습니다. AI를 만들 때 사용한 데이터가 어디에서 왔는지, 그 데이터를 사용할 권리가 있었는지, 그 과정을 설명할 수 있는지가 기업 비용으로 연결될 수 있다는 점입니다.
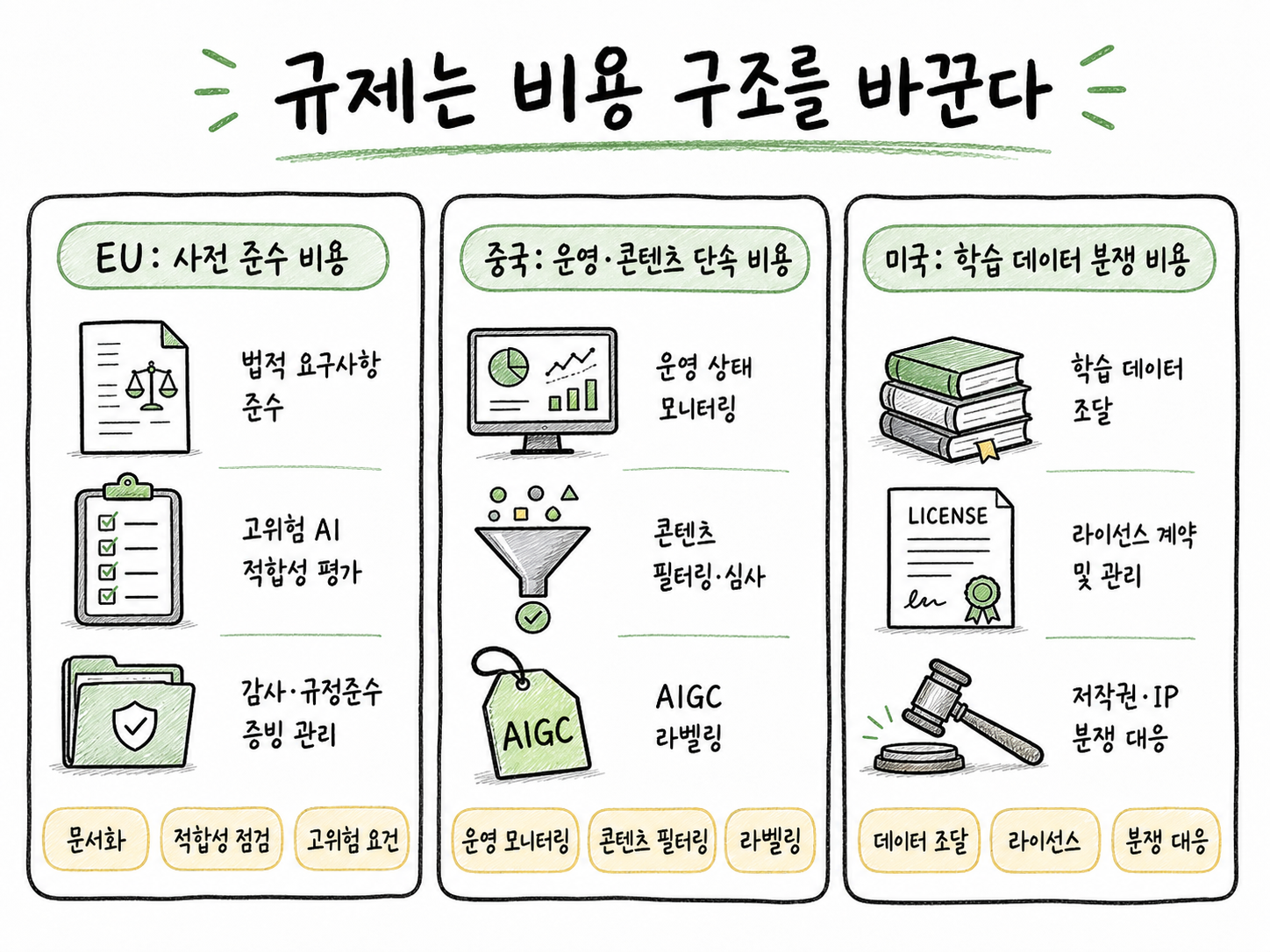
EU, 중국, 미국의 AI 규제·저작권 이슈를 사전 준수 비용, 운영 단속 비용, 학습 데이터 분쟁 비용으로 나누어 비교한 다이어그램
GPU 다음의 비용은 데이터 출처와 운영 기록에서 나온다
AI 기업의 비용을 가장 단순하게 보면 두 가지가 먼저 떠오릅니다. 하나는 모델을 학습시키는 비용이고, 다른 하나는 사용자가 질문할 때마다 답을 만들어내는 비용입니다. 둘 다 많은 계산 자원이 필요합니다.
그런데 규제와 저작권 이슈는 다른 종류의 비용을 만듭니다. 서버를 더 싸게 쓰거나 모델을 더 가볍게 만든다고 해서 해결되지 않는 비용입니다. 데이터를 어떻게 모았는지 기록해야 하고, 권리 문제가 없는지 확인해야 하며, AI가 만든 결과물이라는 표시도 붙여야 합니다.
예를 들어 AI 채용 도구를 만든다고 생각해보겠습니다. 단순히 이력서를 잘 요약하는 것만으로는 부족합니다. 어떤 기준으로 지원자를 평가하는지, 특정 집단에 불리하게 작동하지 않는지, 사람이 최종 판단에 개입할 수 있는지, 나중에 문제가 생겼을 때 판단 과정을 설명할 수 있는지가 중요해집니다.
생성형 AI 서비스도 마찬가지입니다. AI가 만든 글, 이미지, 영상이 사람을 속이거나 사칭에 쓰일 수 있다면 플랫폼은 이를 막기 위한 장치를 갖춰야 합니다. “AI가 만든 콘텐츠입니다”라는 표시, 의심스러운 콘텐츠를 걸러내는 절차, 문제가 생겼을 때 확인할 수 있는 기록이 필요합니다.
학습 데이터 문제는 더 근본적입니다. AI 모델은 많은 데이터를 보고 패턴을 배웁니다. 그런데 그 데이터가 무단으로 수집됐거나, 권리 관계가 불명확하거나, 나중에 권리자가 문제를 제기하면 기업은 소송과 합의 비용을 떠안을 수 있습니다. Anthropic 사례가 보여주는 지점이 바로 여기에 있습니다.
그래서 AI 기업의 비용은 이제 세 층으로 나눠볼 수 있습니다. 첫째는 GPU와 서버 같은 계산 인프라 비용입니다. 둘째는 데이터를 확보하고 권리를 확인하는 데이터 비용입니다. 셋째는 AI가 안전하게 운영되고 있다는 점을 설명하기 위한 관리 비용입니다.
이 흐름은 AI 산업이 성숙해지고 있다는 신호이기도 합니다. 초기에는 “얼마나 똑똑한 모델인가”가 가장 중요했다면, 이제는 “그 모델을 실제 기업과 사회가 믿고 쓸 수 있는가”가 중요해지고 있습니다.
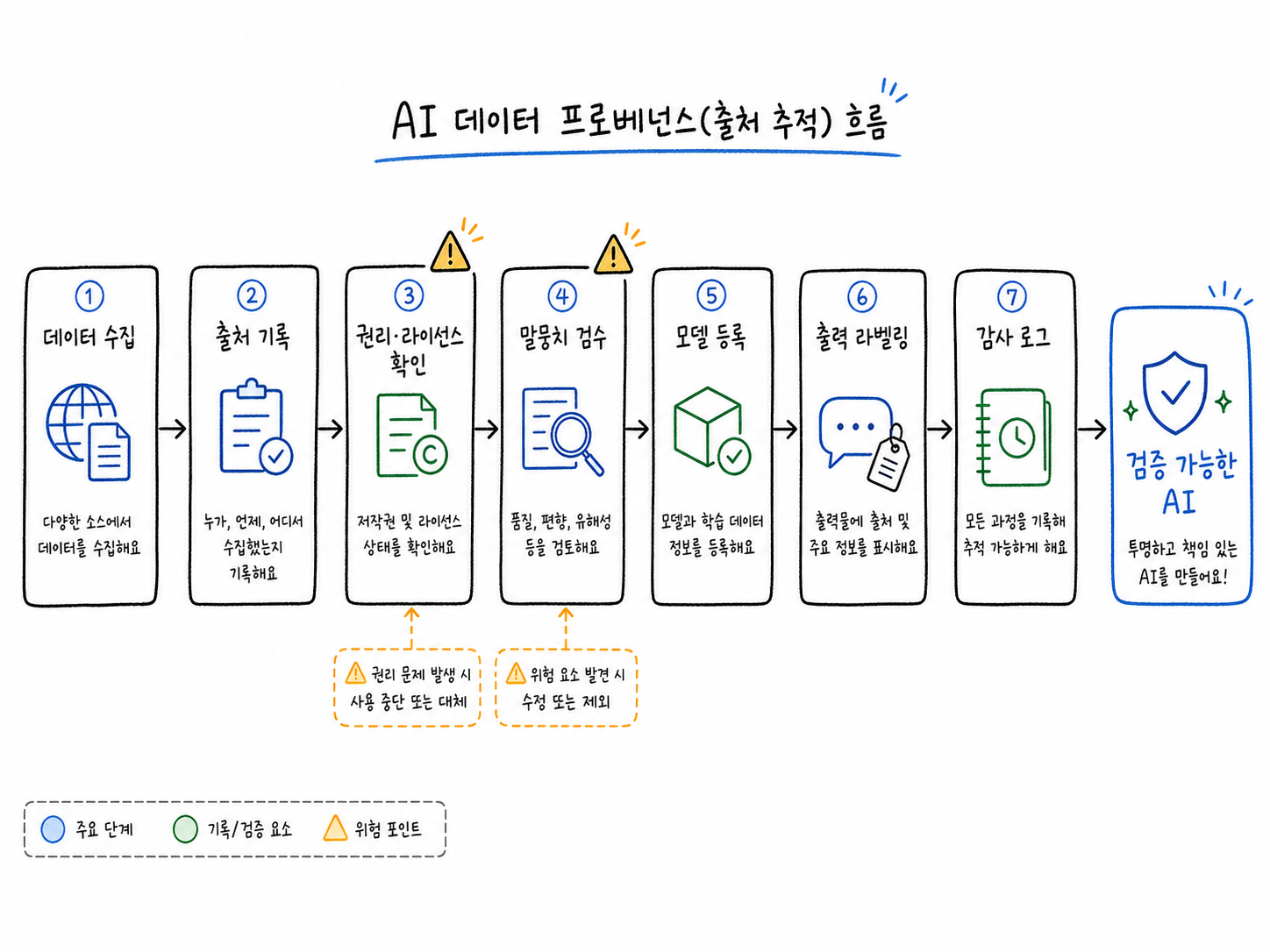
학습 데이터가 수집부터 권리 확인, 말뭉치 검수, 모델 등록, 출력 라벨링, 감사 로그까지 이어지는 데이터 출처 관리 흐름도
EU는 출시 전, 중국은 운영 중, 미국은 학습 데이터 문제를 흔든다
세 사례는 모두 AI 규제와 비용을 보여주지만, 압박이 생기는 지점은 조금씩 다릅니다. EU는 제품을 시장에 내놓기 전의 준비를 강조하고, 중국은 서비스가 운영되는 과정의 관리를 강조하며, 미국 저작권 분쟁은 학습 데이터의 출처와 권리 문제를 드러냅니다.
| 사례 | 쉽게 말하면 | 비용이 생기는 지점 | AI 기업에 주는 의미 |
|---|---|---|---|
| EU AI Act | 사람에게 큰 영향을 줄 수 있는 AI는 더 꼼꼼하게 관리하라는 규제입니다. | 출시 전 검토, 문서화, 사람의 감독, 문제 발생 시 설명할 수 있는 기록 | 기능을 빨리 만드는 것만큼, 어떤 위험이 있는지 미리 분류하는 일이 중요해집니다. |
| 중국 AI 애플리케이션 관리 강화 캠페인 | AI 앱이 허위정보, 사칭, 부적절한 콘텐츠에 쓰이지 않도록 운영 단계에서 관리하라는 흐름입니다. | 모델 등록, 보안 심사, AI 생성물 표시, 콘텐츠 관리, 학습용 데이터 안전성 점검 | AI 서비스는 출시 후에도 계속 감시하고 관리하는 운영 체계가 필요합니다. |
| Anthropic 저작권 합의 사례 | AI가 학습한 데이터의 출처와 권리 문제가 큰 비용으로 돌아올 수 있음을 보여준 사례입니다. | 데이터 라이선스, 저작권 검토, 소송 대응, 합의금, 데이터 보관 정책 | 데이터를 많이 모으는 것보다, 어떤 데이터를 합법적으로 썼는지 설명하는 능력이 중요해집니다. |
AI 기업은 좋은 모델보다 설명 가능한 운영을 준비해야 한다
이 변화는 AI 기업만의 이야기가 아닙니다. AI 서비스를 쓰려는 기업, AI 스타트업을 보는 투자자, 생성형 AI 트렌드를 따라가는 사람 모두에게 중요한 변화입니다. 이제 AI 제품을 볼 때 “성능이 좋은가”만 물어서는 부족합니다.
먼저 데이터 출처를 봐야 합니다. AI가 어떤 데이터를 보고 배웠는지, 그 데이터에 저작권 문제는 없는지, 문제가 생겼을 때 그 데이터를 추적할 수 있는지가 중요합니다. 이 부분이 약하면 모델이 아무리 좋아도 나중에 법적 비용이 커질 수 있습니다.
다음은 운영 방식입니다. AI가 만든 콘텐츠를 표시하는지, 허위정보나 사칭에 악용되는 것을 막는지, 민감한 영역에서는 사람이 개입할 수 있는지 확인해야 합니다. 특히 채용, 금융, 의료, 교육처럼 사람의 기회와 권리에 영향을 주는 영역에서는 이 문제가 더 중요해집니다.
마지막은 설명 가능성입니다. 여기서 말하는 설명 가능성은 어려운 기술 용어만 뜻하지 않습니다. 문제가 생겼을 때 “왜 이런 결과가 나왔는지”, “어떤 데이터와 절차를 거쳤는지”, “사람이 어디에서 확인했는지”를 보여줄 수 있는 능력입니다.
이런 준비는 당장 눈에 띄는 기능은 아닙니다. 하지만 기업 고객이 AI를 실제 업무에 도입할 때는 매우 중요합니다. 회사 입장에서는 똑똑하지만 위험한 도구보다, 조금 느리더라도 통제 가능하고 설명 가능한 도구를 선호할 수 있기 때문입니다.
결국 규제 대응은 단순히 법무팀이 처리할 일이 아닙니다. 제품 기획, 데이터 수집, 모델 개발, 서비스 운영, 고객 커뮤니케이션이 함께 바뀌어야 합니다. 앞으로는 이 과정을 자연스럽게 제품 안에 녹여낸 기업이 더 강한 신뢰를 얻을 가능성이 큽니다.
AI 산업의 다음 경쟁력은 성능과 신뢰의 조합이다
AI 산업의 비용 경쟁은 GPU에서 끝나지 않습니다. GPU는 여전히 중요합니다. 하지만 규제와 저작권 문제가 커질수록 데이터 출처를 증명하고, AI 생성물을 표시하고, 문제가 생겼을 때 과정을 설명하는 능력도 비용 구조의 핵심이 됩니다.
EU는 출시 전 위험 관리와 문서화를 강조합니다. 중국은 운영 중 콘텐츠 관리와 AI 생성물 표시를 강조합니다. Anthropic 저작권 합의 사례는 학습 데이터의 출처와 권리 문제가 얼마나 큰 비용으로 돌아올 수 있는지 보여줍니다.
세 흐름은 서로 다르지만 한 방향을 가리킵니다. AI 기업은 이제 “좋은 모델을 만드는 회사”를 넘어 “그 모델을 믿고 쓸 수 있게 운영하는 회사”가 되어야 합니다. 앞으로의 AI 경쟁력은 성능과 신뢰를 함께 증명하는 능력에서 갈릴 가능성이 큽니다.
자주 묻는 질문으로 핵심을 다시 정리한다
Q. AI 규제가 모델 성능을 낮추나요?
그렇게 단정하기는 어렵습니다. 규제는 모델의 똑똑함보다 제품 출시 속도, 데이터 관리, 저작권 검토, AI 생성물 표시, 운영 기록 관리 같은 비용에 더 직접적인 영향을 줍니다.
Q. 모든 AI 서비스가 강한 규제를 받게 되나요?
아닙니다. 핵심은 용도입니다. 단순한 보조 도구와 달리 채용, 의료, 신용평가, 법집행, 생체인식처럼 사람의 권리와 기회에 큰 영향을 줄 수 있는 AI는 더 엄격한 관리를 받을 수 있습니다.
Q. 중국의 AI 관리 강화는 허위정보만 막는 정책인가요?
아닙니다. 허위정보와 사칭 콘텐츠 대응도 포함되지만, 모델 등록, 보안 심사, 학습용 데이터 안전성, AI 생성 콘텐츠 표시, 오용 콘텐츠 차단까지 함께 다루는 운영 관리에 가깝습니다.
Q. Anthropic 저작권 합의 사례에서 봐야 할 핵심은 무엇인가요?
AI 학습 데이터가 어디에서 왔는지 설명하지 못하면 큰 비용으로 돌아올 수 있다는 점입니다. 이 사례를 AI 학습 전체의 합법·불법 문제로 단순화하기보다, 데이터 출처와 권리 관리의 중요성을 보여주는 사례로 보는 편이 자연스럽습니다.
Q. AI 기업을 볼 때 앞으로 무엇을 더 봐야 하나요?
모델 성능만 보지 말고 데이터 출처, 저작권 관리, AI 생성물 표시, 운영 기록, 문제 발생 시 설명 가능성을 함께 봐야 합니다. 앞으로는 기술력과 신뢰 관리 능력이 함께 경쟁력이 될 가능성이 큽니다.