핵심 요약
- Google Cloud의 TPU 8t와 TPU 8i 분리는 AI 인프라가 “하나의 거대한 학습 클러스터”에서 “워크로드별로 다른 병목을 푸는 인프라”로 이동하고 있음을 보여줍니다.
- TPU 8t는 대규모 pre-training, embedding-heavy workload, 데이터 이동, 스토리지, 네트워크 확장성 같은 학습 병목에 초점을 맞춘 시스템입니다.
- TPU 8i는 post-training, serving, reasoning, long-context decoding, KV cache, sampling, latency처럼 실제 서비스 운영에서 반복적으로 발생하는 추론 병목을 겨냥합니다.
- NVIDIA, Groq, Cerebras의 전략을 함께 보면 이제 AI 칩 경쟁은 “칩 하나의 FLOPS”보다 “칩 + 메모리 + 네트워크 + 서빙 소프트웨어”의 조합으로 판단해야 합니다.
- 앞으로 AI 인프라를 볼 때는 파라미터 수와 학습 성능만이 아니라 latency, tokens/sec, 동시 사용자 수, KV cache, serving cost, workload별 최적화 여부를 함께 봐야 합니다.
목차
학습 칩보다 추론 칩이 중요해지는 이유
안녕하세요? 오늘 다룰 주제는 Google Cloud의 8세대 TPU 발표가 보여준 AI 인프라 경쟁의 방향 변화입니다. 겉으로 보면 TPU 8t와 TPU 8i라는 두 개의 칩 발표처럼 보이지만, 조금 더 들여다보면 AI 산업의 병목이 어디로 이동하고 있는지를 보여주는 중요한 신호에 가깝습니다.
지난 몇 년 동안 AI 인프라 경쟁은 주로 “얼마나 큰 모델을 얼마나 빨리 학습하느냐”에 집중됐습니다. 더 많은 GPU, 더 큰 클러스터, 더 높은 FLOPS, 더 빠른 학습 시간이 핵심 지표였습니다. 하지만 에이전트형 AI 서비스가 늘어나면 문제는 조금 달라집니다. 모델을 한 번 학습하는 비용도 중요하지만, 실제 서비스에서는 사용자가 요청할 때마다 모델이 계속 실행됩니다.
이때 운영자가 보는 지표는 “이 모델이 몇 조 개 파라미터인가”만이 아닙니다. 첫 토큰이 얼마나 빨리 나오는지, 동시에 몇 명을 처리할 수 있는지, 긴 문맥을 넣었을 때 비용이 얼마나 늘어나는지, 에이전트가 여러 번 생각하고 도구를 호출할 때 latency가 얼마나 쌓이는지가 중요해집니다. Google Cloud가 TPU 8t와 TPU 8i를 나눈 이유도 바로 여기에 있습니다.
Google Cloud는 2026년 4월 23일 공개한 공식 딥다이브에서 pre-training, post-training, real-time serving의 인프라 요구사항이 서로 달라졌기 때문에 8세대 TPU를 두 개의 전문화된 시스템으로 설계했다고 설명했습니다. 이 글에서는 이 발표를 단순한 칩 스펙 뉴스가 아니라, AI 인프라 경쟁이 학습 중심에서 추론·서빙·에이전트 실행 최적화로 이동하는 흐름으로 읽어보겠습니다.
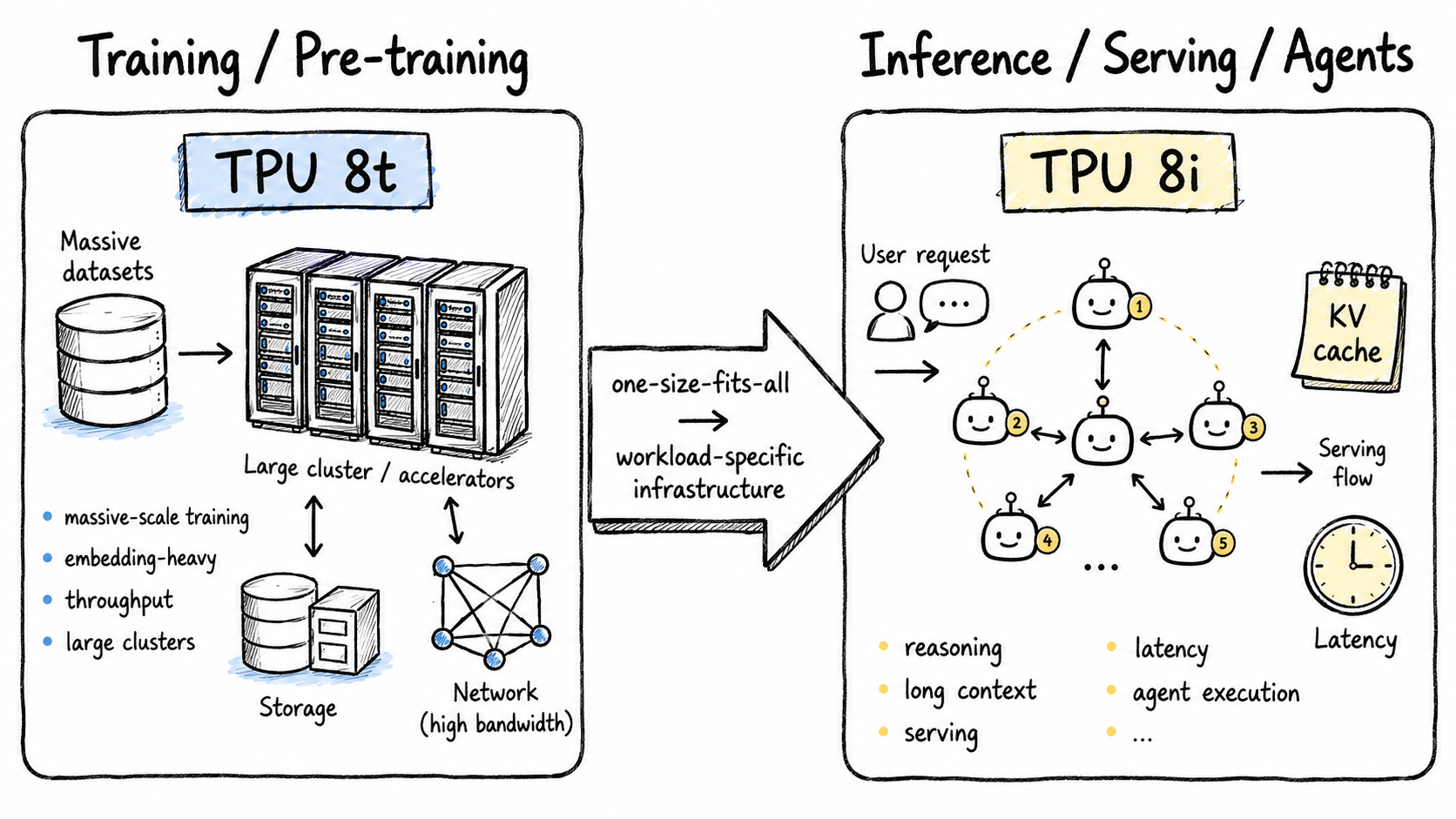
학습 중심 AI 인프라와 추론·에이전트 실행 중심 AI 인프라가 분화되는 구조도
TPU 8t와 TPU 8i는 무엇인가
TPU는 Google이 AI 워크로드를 위해 설계한 전용 가속기입니다. Google Cloud의 제품 페이지는 TPU가 에이전트, 코드 생성, 대규모 언어 모델, 미디어 생성, 음성, 비전, 추천, 개인화 모델 같은 AI 워크로드에 쓰이는 맞춤형 가속기라고 설명합니다.
이번에 중요한 점은 Google Cloud가 8세대 TPU를 하나의 범용 제품으로만 제시하지 않았다는 것입니다. TPU 8t는 training의 t로 이해할 수 있을 만큼 대규모 pre-training과 embedding-heavy workload에 초점이 맞춰져 있습니다. 공식 딥다이브에 따르면 TPU 8t는 9,600개 칩으로 구성되는 single superpod, 3D torus 네트워크, SparseCore, Virgo Network, TPUDirect Storage 등을 통해 학습 과정에서 발생하는 데이터 이동과 클러스터 확장 병목을 줄이려는 시스템입니다.
반면 TPU 8i는 inference의 i에 가깝습니다. Google Cloud는 TPU 8i를 post-training, high-concurrency reasoning, sampling, serving에 최적화된 시스템으로 설명합니다. 특히 384MB on-chip SRAM, CAE라고 부르는 Collectives Acceleration Engine, serving-optimized network topology인 Boardfly가 핵심 요소로 제시됩니다.
쉽게 말하면 TPU 8t는 거대한 모델을 만드는 공장에 가깝고, TPU 8i는 만들어진 모델을 수많은 사용자에게 빠르고 저렴하게 응답하게 만드는 서비스 엔진에 가깝습니다. 두 시스템이 모두 AI lifecycle을 지원할 수는 있지만, Google이 굳이 둘을 나눈 것은 학습과 추론의 병목이 더 이상 같지 않다는 뜻입니다.
Google Cloud가 발표한 핵심 변화
Google Cloud의 발표에서 가장 먼저 확인해야 할 것은 출시 상태입니다. Google Cloud TPU 제품 페이지 기준으로 TPU 8t와 TPU 8i의 Availability는 모두 Coming soon으로 표시되어 있습니다. Blog.Google의 공식 글은 두 칩이 “later this year” 일반 제공될 예정이라고 설명합니다. 따라서 현재 확인 가능한 범위에서는 “발표됨” 또는 “출시 예정”으로 표현하는 것이 정확하고, 모든 리전에서 일반 고객이 바로 쓸 수 있다고 단정하면 안 됩니다.
스펙 측면에서 TPU 8t는 대규모 학습에 필요한 처리량과 확장성을 강조합니다. Google은 TPU 8t가 9,600개 칩의 superpod, 2PB shared high bandwidth memory, 121 ExaFLOPS compute를 제공한다고 설명합니다. 또한 Virgo Network와 JAX, Pathways를 결합해 대규모 학습 클러스터를 확장할 수 있다고 주장합니다. 이 수치들은 Google 발표 기준이며, 실제 고객 워크로드에서의 결과는 모델 구조, 데이터 파이프라인, 리전, 사용 가능한 서비스 형태에 따라 달라질 수 있습니다.
TPU 8i는 다른 방향을 봅니다. Google Cloud는 TPU 8i가 384MB on-chip SRAM으로 KV cache를 더 많이 온칩에 둘 수 있고, long-context decoding에서 코어가 쉬는 시간을 줄이는 데 도움이 된다고 설명합니다. 또한 CAE는 auto-regressive decoding과 chain-of-thought 처리에서 필요한 reduction과 synchronization 단계를 가속하고, Boardfly는 all-to-all communication의 hop 수를 줄여 latency를 낮추는 구조로 설명됩니다.
여기서 핵심은 “더 큰 칩”이 아니라 “다른 병목을 겨냥한 칩”입니다. TPU 8t가 학습 중 데이터와 연산을 끊김 없이 공급하는 데 집중한다면, TPU 8i는 긴 문맥, 반복 추론, 많은 동시 요청, 에이전트 실행에서 발생하는 지연과 메모리 압박을 줄이는 데 집중합니다.
왜 AI 병목은 학습에서 추론으로 이동하나
AI 모델을 만드는 과정과 AI 서비스를 운영하는 과정은 경제 구조가 다릅니다. 학습은 큰 비용이 한 번 또는 몇 번 크게 발생하는 이벤트에 가깝습니다. 물론 frontier model 학습 비용은 막대하지만, 완료된 뒤에는 같은 모델을 수많은 요청에 반복적으로 사용합니다.
추론은 반복 비용입니다. 사용자가 질문할 때마다, 에이전트가 계획을 세울 때마다, 도구를 호출하고 다시 답변을 정리할 때마다 모델이 실행됩니다. NVIDIA도 LLM inference를 설명하면서 foundation model은 학습뿐 아니라 inference에서도 memory와 compute를 많이 쓰고, inference는 반복적으로 발생하는 비용이라고 설명합니다.
특히 에이전트 서비스는 단순 챗봇보다 비용 구조가 더 복잡합니다. 한 번의 사용자 요청이 여러 하위 작업으로 쪼개지고, 각 작업이 다시 모델 호출, 검색, 코드 실행, 검증, 요약으로 이어질 수 있습니다. Google Cloud도 agentic era에서는 하나의 intent가 여러 specialized agent의 협업과 state 보존, reinforcement learning 흐름으로 이어진다고 설명했습니다.
이때 병목은 단순히 “GPU가 빠른가”가 아닙니다. 첫 응답까지 걸리는 시간인 TTFT, 초당 생성 토큰 수인 tokens/sec, 동시에 처리할 수 있는 사용자 수, 긴 문맥에서 KV cache를 얼마나 효율적으로 관리하는지, peak latency가 아니라 tail latency를 얼마나 안정적으로 잡는지가 중요해집니다.
비유하자면 학습 인프라는 거대한 책을 쓰는 인쇄소이고, 추론 인프라는 그 책을 바탕으로 매일 수백만 명의 질문에 답하는 콜센터입니다. 인쇄소에서는 한 번에 대량 생산하는 효율이 중요하지만, 콜센터에서는 대기 시간, 상담원 배치, 이전 대화 기록, 동시 문의 처리량이 훨씬 중요합니다.
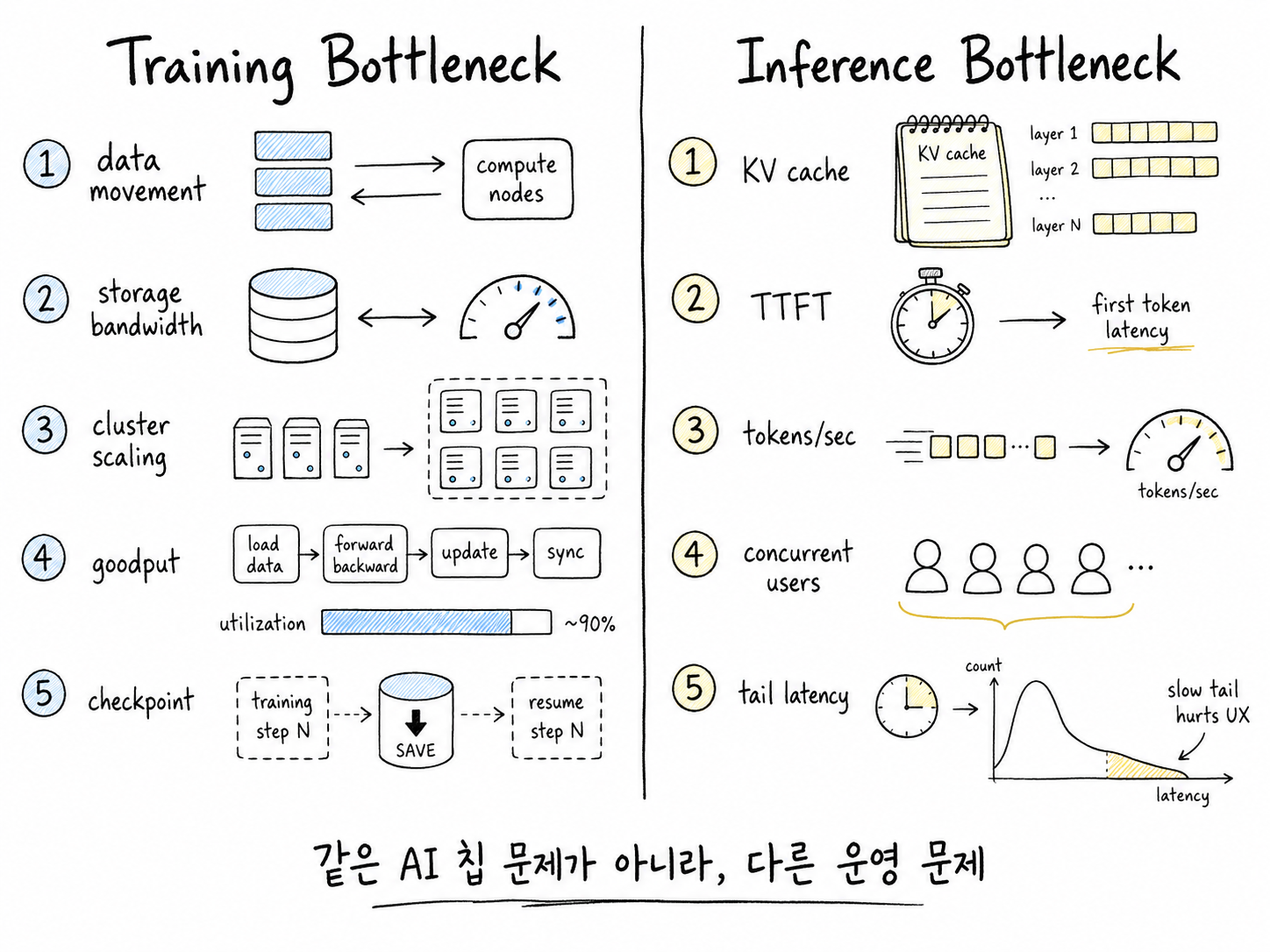
학습 병목과 추론 병목의 차이를 설명하는 손그림 비교표
TPU 8t와 TPU 8i가 겨냥한 병목의 차이
학습 병목은 주로 “큰 데이터를 큰 모델에 얼마나 끊기지 않고 공급하느냐”의 문제입니다. 대규모 pre-training에서는 수많은 칩이 같은 목표를 향해 동기화되어야 하고, 데이터셋은 거대하며, checkpoint와 storage access도 전체 학습 시간을 좌우합니다. Google Cloud가 TPU 8t에서 TPUDirect Storage, Virgo Network, SparseCore, 3D torus를 강조하는 이유는 이 때문입니다.
반면 추론 병목은 “각 요청을 얼마나 빨리, 싸게, 안정적으로 처리하느냐”의 문제입니다. 특히 LLM은 한 번에 문장 전체를 뱉는 것이 아니라 토큰을 하나씩 생성합니다. 이 과정을 auto-regressive decoding이라고 부릅니다. 첫 단어를 만들고, 그 단어를 반영해 다음 단어를 만들고, 다시 다음 단어를 만드는 식입니다.
여기서 KV cache가 중요해집니다. KV cache는 모델이 이전 토큰을 읽으며 계산해둔 key와 value 정보를 저장한 “작업 메모장”이라고 생각하면 됩니다. 같은 앞부분을 매번 다시 읽고 계산하지 않도록 해주기 때문에 추론을 빠르게 만듭니다. 하지만 NVIDIA의 KV cache 설명처럼 이 cache는 language model 크기, batched request 수, sequence context length에 따라 커지고, memory requirement를 빠르게 증가시킵니다.
long-context decoding은 이 메모장이 아주 길어지는 상황입니다. 예를 들어 사용자가 긴 계약서, 여러 문서, 긴 대화 기록을 넣으면 모델은 더 많은 이전 정보를 참고해야 합니다. KV cache는 재계산을 줄여주지만, 동시에 메모리를 많이 차지합니다. 최근 연구들도 KV cache 크기가 context length에 따라 선형적으로 증가하고 long-context inference에서 memory usage와 decoding latency의 병목이 된다고 설명합니다.
sampling은 모델이 다음 토큰 후보 중 무엇을 고를지 결정하는 과정입니다. 겉으로는 작은 작업처럼 보이지만, reasoning model이나 MoE 모델에서는 여러 칩, 여러 expert, 여러 단계의 동기화가 얽힐 수 있습니다. Google Cloud가 TPU 8i에 CAE를 넣어 reduction과 synchronization 단계를 줄이고, Boardfly로 all-to-all communication hop 수를 낮추려 한 이유가 여기에 있습니다.
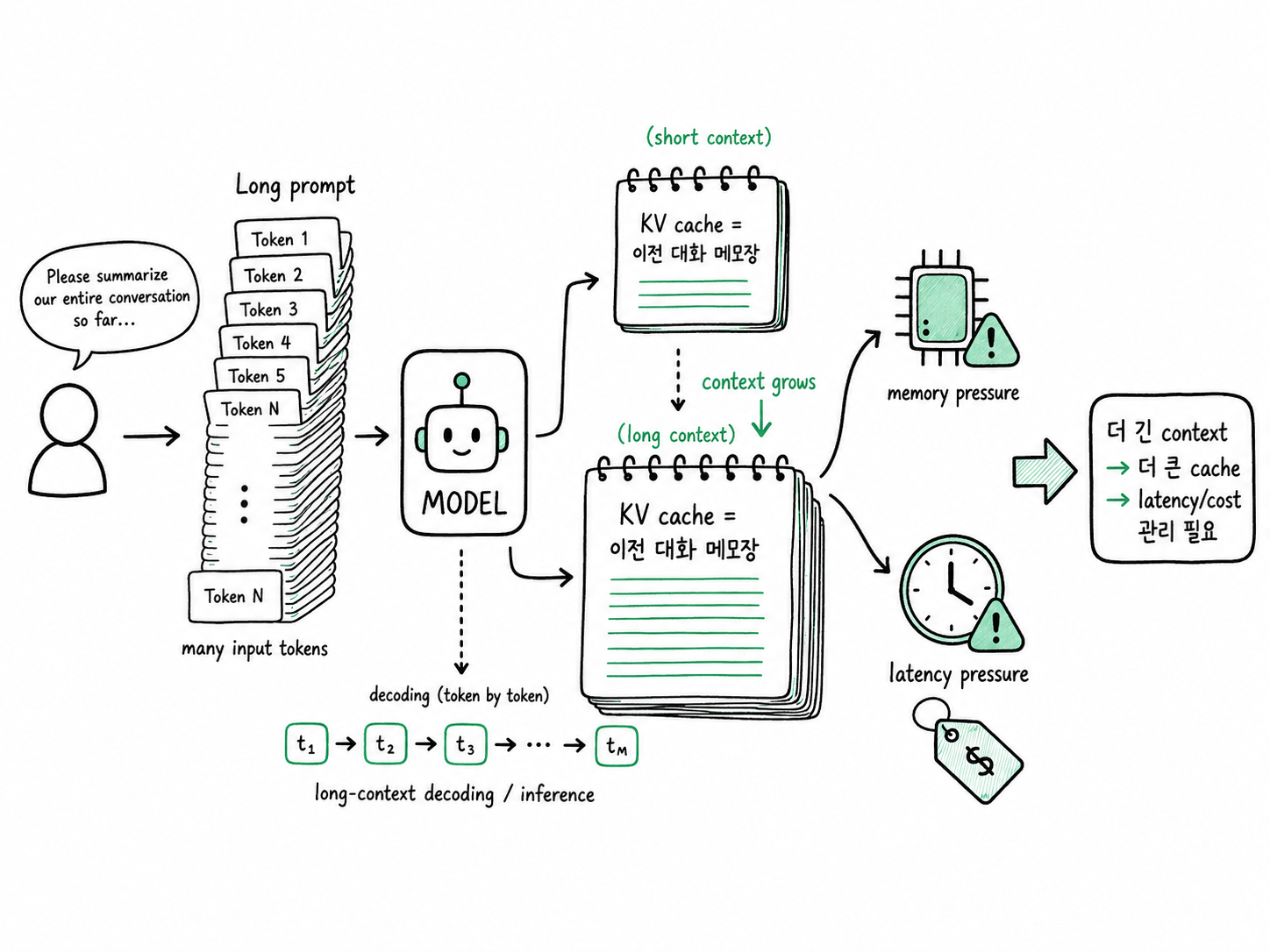
long-context decoding에서 KV cache가 메모리와 latency 병목이 되는 과정을 설명하는 개념도
Google, NVIDIA, Groq, Cerebras의 추론 인프라 전략 비교
이 흐름은 Google만의 이야기가 아닙니다. NVIDIA, Groq, Cerebras도 모두 다른 방식으로 추론 병목을 겨냥하고 있습니다. 중요한 것은 어느 회사가 “무조건 이긴다”가 아니라, 각 회사가 어떤 병목을 핵심 문제로 보고 있는지입니다.
| 구분 | 주로 겨냥하는 병목 | 대표 접근 | 읽어야 할 포인트 |
|---|---|---|---|
| Google Cloud TPU 8t | 대규모 pre-training, embedding-heavy workload, 데이터 이동, 클러스터 확장 | 3D torus, SparseCore, Virgo Network, TPUDirect Storage | 학습 시간을 줄이는 것보다 “학습 클러스터가 놀지 않게 하는 것”이 핵심 |
| Google Cloud TPU 8i | serving, reasoning, long-context decoding, KV cache, sampling latency | 384MB SRAM, CAE, Boardfly topology, HBM 288GB | 에이전트와 MoE 추론에서 latency와 cache 관리가 중요해짐 |
| NVIDIA TensorRT-LLM·Dynamo | GPU fleet 기반 대규모 LLM serving, routing, memory management | inference runtime, disaggregated serving, KV-aware router, KV Block Manager | 칩만이 아니라 서빙 소프트웨어가 성능과 비용을 좌우 |
| Groq LPU | 예측 가능한 token generation latency | single-core, on-chip SRAM, static scheduling, direct chip-to-chip connectivity | 범용성보다 deterministic inference 경험을 강조 |
| Cerebras Inference / WSE | 빠른 token generation, wafer-scale 기반 단순화 | wafer-scale processor, Cerebras Inference Cloud | 대규모 칩 구조로 interconnect 복잡성을 줄이려는 접근 |
NVIDIA의 접근은 특히 소프트웨어 스택 측면에서 중요합니다. TensorRT-LLM은 NVIDIA GPU에서 LLM inference를 최적화하기 위한 오픈소스 라이브러리로 소개되고, modular Python runtime, PyTorch-native model authoring, production API를 포함합니다. Dynamo는 distributed environment에서 generative AI model을 serving하기 위한 open-source, low-latency, modular inference framework로 설명되며, request routing, optimized memory management, disaggregated inference, KV-aware router, KV Block Manager 같은 요소를 포함합니다.
Groq는 LPU를 “inference를 위해 설계된” 구조로 설명합니다. 공식 페이지는 single-core architecture, on-chip SRAM, static scheduling, direct chip-to-chip connectivity를 통해 predictable performance를 제공한다고 주장합니다. 이는 “대형 GPU를 잘 나눠 쓰는 방식”보다 “처음부터 토큰 실행 흐름을 예측 가능하게 만들자”는 쪽에 가깝습니다.
Cerebras는 wafer-scale 전략을 전면에 둡니다. Cerebras Inference 페이지는 최대 15배 빠른 inference, 3,000 tokens/sec 같은 수치를 제시하지만, 이는 Cerebras의 공개 자료 기준이며 실제 워크로드별 검증이 필요합니다. Cerebras의 WSE-3 페이지는 46,225mm², 4조 개 transistor, 900,000 AI-optimized core를 가진 wafer-scale chip이라고 설명합니다. 이 접근은 여러 칩을 네트워크로 묶는 복잡성을 줄이고, 하나의 거대한 칩에서 inference를 빠르게 처리하려는 전략으로 볼 수 있습니다.
결국 공통점은 분명합니다. 이제 AI 인프라 경쟁은 “가장 빠른 칩 하나”의 문제가 아닙니다. 실제 경쟁 단위는 chip, HBM, SRAM, interconnect, routing, cache manager, inference runtime, Kubernetes orchestration, pricing model이 결합된 전체 serving stack입니다.
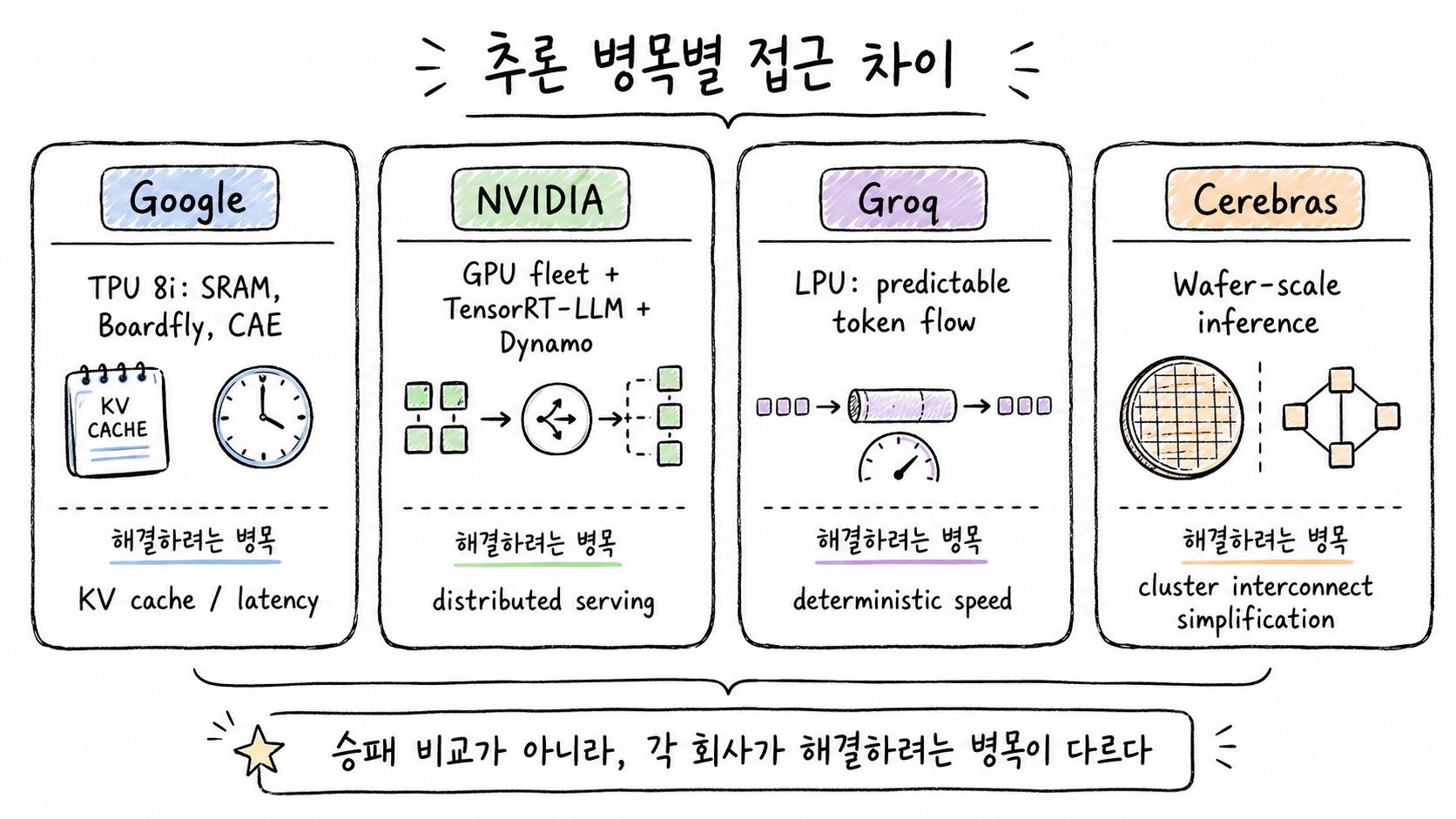
Google, NVIDIA, Groq, Cerebras가 각각 다른 추론 병목을 해결하려는 방향을 비교한 구조도
아직 확인해야 할 부분
가장 먼저 확인해야 할 것은 실제 사용 가능 여부입니다. 앞서 본 것처럼 Google Cloud TPU 제품 페이지는 TPU 8t와 TPU 8i 모두 Coming soon으로 표시합니다. 따라서 일반 고객이 어떤 리전에서, 어떤 가격 정책으로, 어떤 quota와 SLA 아래 사용할 수 있는지는 추가 확인이 필요합니다.
둘째, 성능·가격 효율 수치는 공급사 발표 기준으로 봐야 합니다. Google은 TPU 8t가 Ironwood 대비 large-scale training에서 최대 2.7배 performance-per-dollar 개선, TPU 8i가 large MoE model의 low-latency inference에서 최대 80% performance-per-dollar 개선을 제공한다고 설명합니다. 하지만 이 수치는 모델 종류, batch size, context length, precision, serving target, 지역별 가격, 예약 조건에 따라 달라질 수 있습니다.
셋째, long-context와 KV cache 최적화는 모든 모델에서 같은 결과를 내지 않습니다. NVIDIA도 NVFP4 KV cache 최적화를 설명하면서 context length, batch size, cache-hit rate, memory bandwidth가 성능에 영향을 준다고 설명합니다. 즉 “KV cache를 온칩에 더 많이 둔다”는 방향은 중요하지만, 그것만으로 모든 추론 비용 문제가 해결된다고 보면 안 됩니다.
넷째, 프레임워크 지원 상태도 확인해야 합니다. Google Cloud는 native PyTorch support for TPUs가 preview라고 설명합니다. 실무자가 실제로 이전할 때는 JAX, PyTorch, vLLM, SGLang, XLA, Pathways 지원 범위와 운영 편의성, 기존 MLOps 파이프라인과의 통합 비용까지 확인해야 합니다.
마지막으로 NVIDIA, Groq, Cerebras의 비교는 승패 판정으로 읽으면 안 됩니다. 각 회사의 공개 수치는 자사 환경과 벤치마크 조건을 전제로 합니다. 실제 구매나 아키텍처 선택에서는 모델 구조, 목표 latency, 사용량 변동성, 지역, 데이터 보안, vendor lock-in, 엔지니어링 역량까지 함께 봐야 합니다.
AI 인프라 경쟁을 읽는 새로운 관점
이번 TPU 8세대 발표가 흥미로운 이유는 Google이 “더 큰 학습 칩”만 이야기하지 않았기 때문입니다. 오히려 Google은 training과 inference가 서로 다른 병목을 갖는다고 전제하고, 두 시스템을 나눠 설계했다는 메시지를 강조했습니다.
이 관점은 AI 서비스 기획자와 개발자에게도 중요합니다. 예전에는 “어떤 모델이 가장 똑똑한가”가 중심 질문이었다면, 이제는 “이 모델을 실제 서비스에서 얼마에, 얼마나 빠르게, 얼마나 안정적으로 운영할 수 있는가”가 같은 비중의 질문이 됩니다.
예를 들어 AI 에이전트 서비스를 만든다고 가정해보겠습니다. 사용자가 “이번 분기 매출 데이터를 분석하고, 문제점을 찾고, 개선안을 문서로 만들어줘”라고 요청합니다. 이 요청은 한 번의 모델 호출로 끝나지 않습니다. 데이터 조회, 요약, 가설 생성, 계산, 검증, 문서 작성, 재검토가 이어질 수 있습니다. 각 단계마다 모델 호출이 발생하고, 이전 단계의 context가 다음 단계로 넘어갑니다.
이때 비용은 training cluster가 아니라 serving system에서 터질 가능성이 큽니다. 응답이 늦으면 사용자는 이탈하고, cache 관리가 안 되면 GPU나 TPU 메모리가 낭비되며, routing이 비효율적이면 같은 모델을 쓰면서도 비용이 크게 늘어납니다. 그래서 latency, tokens/sec, TTFT, P99 latency, KV cache hit rate, serving cost per request 같은 지표가 점점 더 중요해집니다.
AI 인프라를 보는 관점도 바뀌어야 합니다. 단순히 “어느 회사 칩이 더 빠른가”가 아니라, “어떤 workload에서 어떤 병목을 줄이는가”를 물어야 합니다. 학습용 칩, 추론용 칩, reasoning용 시스템, 에이전트 실행용 CPU·orchestration layer가 서로 다른 역할을 하게 될 가능성이 큽니다.
이 글에서 얻을 수 있는 인사이트
첫 번째 인사이트는 AI 인프라가 통합이 아니라 분화의 방향으로 가고 있다는 점입니다. 과거에는 거대한 GPU 클러스터 하나가 training도 하고 inference도 하는 그림이 자연스러웠습니다. 하지만 Google의 TPU 8t와 TPU 8i 분리는 앞으로 workload별로 다른 하드웨어와 소프트웨어 조합이 쓰일 수 있음을 보여줍니다.
두 번째 인사이트는 inference가 단순한 “모델 실행”이 아니라 하나의 독립된 운영 산업이 되고 있다는 점입니다. NVIDIA의 Dynamo가 KV-aware router와 KV Block Manager를 강조하고, Google이 TPU 8i에서 SRAM과 Boardfly, CAE를 강조하는 것은 같은 방향을 가리킵니다. 추론은 이제 모델을 올려두고 API만 열면 되는 문제가 아니라, cache, routing, batching, memory tiering, network latency를 함께 다루는 시스템 문제가 됐습니다.
세 번째 인사이트는 에이전트 시대의 비용 단위가 달라진다는 점입니다. 챗봇은 한 번 묻고 한 번 답하는 구조에 가까웠지만, 에이전트는 여러 번 생각하고, 여러 도구를 호출하고, 중간 결과를 다시 읽습니다. 즉 한 번의 사용자 요청이 내부적으로는 여러 번의 inference request로 증폭될 수 있습니다. 이 구조에서는 모델의 지능뿐 아니라 inference economics가 제품의 마진과 사용자 경험을 결정합니다.
네 번째 인사이트는 벤치마크를 읽는 방식입니다. 앞으로 AI 인프라 발표를 볼 때는 peak FLOPS만 보지 말아야 합니다. context length가 얼마인지, batch size가 어떤지, latency target이 무엇인지, long-context에서 cache miss가 얼마나 나는지, concurrent user가 늘 때 tail latency가 어떻게 변하는지 봐야 합니다. 또한 공급사 발표 수치인지, 독립 벤치마크인지, 실제 고객 워크로드인지도 구분해야 합니다.
결론
Google Cloud의 TPU 8t와 TPU 8i 발표는 단순히 “새 TPU가 나왔다”는 뉴스가 아닙니다. 더 중요한 메시지는 AI 인프라 경쟁이 대규모 학습 칩 중심에서 추론, 서빙, reasoning, 에이전트 실행 최적화 중심으로 넓어지고 있다는 점입니다.
TPU 8t는 거대한 모델을 학습시키는 병목을 줄이는 방향입니다. 데이터 이동, embedding-heavy workload, 스토리지, 네트워크, superpod 확장성이 핵심입니다. 반면 TPU 8i는 실제 서비스에서 반복적으로 발생하는 추론 병목을 겨냥합니다. long-context decoding, KV cache, sampling, high-concurrency reasoning, latency가 핵심입니다.
NVIDIA, Groq, Cerebras의 전략을 함께 보면 이 흐름은 더 분명해집니다. NVIDIA는 GPU fleet 위의 inference software stack을 강화하고, Groq는 inference에 특화된 예측 가능한 토큰 실행을 강조하며, Cerebras는 wafer-scale 기반의 빠른 inference를 내세웁니다. Google은 TPU를 학습용과 추론용으로 나누며 AI Hypercomputer 안에서 chip, network, memory, software를 함께 설계하는 방향을 보여줍니다.
따라서 앞으로 AI 인프라 경쟁을 볼 때는 “어느 칩이 가장 강한가”보다 “어떤 workload의 어떤 병목을 줄이는가”를 먼저 봐야 합니다. 학습 성능은 여전히 중요하지만, 에이전트 시대의 제품 경쟁력은 매 요청마다 반복되는 inference 비용, latency, KV cache 관리, 동시 처리량, serving software stack에서 갈릴 가능성이 큽니다.
그럼 다음 주제로 찾아뵙겠습니다. 글 읽어주셔서 감사합니다.