핵심 요약
- 행정안전부가 발표한 개방형 문서 형식 준수 의무화는 단순한 파일 저장 방식 변경이 아니라, AI가 행정문서를 검색·추출·요약·재활용할 수 있게 만드는 공공 AI 인프라 정책으로 볼 수 있습니다.
- AI 행정 자동화는 챗봇이나 LLM을 도입한다고 완성되지 않습니다. 문서 구조, 메타데이터, 접근성, 호환성, 공공데이터 표준이 함께 정비되어야 실제 업무 자동화 품질이 올라갑니다.
- RAG 기반 행정 AI는 문서가 잘게 나뉘고, 검색 가능하고, 근거를 추적할 수 있어야 성능이 좋아집니다. 이미지 PDF, 폐쇄형 문서, 비정형 파일이 많을수록 답변 품질은 떨어질 수 있습니다.
- 2026년 5월 18일부터 중앙·지방 온나라 문서시스템에 개방형 문서만 첨부하도록 의무화한다는 내용은 행정문서의 작성·유통 단계부터 AI 활용성을 고려하겠다는 의미로 해석할 수 있습니다.
- 다만 HWPX, PDF, DOCX 등 구체 파일 형식별 허용 여부와 세부 예외 기준은 공개 자료 기준으로 단정하지 말고, 최종 법령 조문과 운영 지침을 추가 확인해야 합니다.
목차
AI 정부라는 말보다 먼저 봐야 할 것
안녕하세요? 오늘 다룰 주제는 “AI 정부의 시작은 챗봇이 아니라 문서 형식이다”라는 관점입니다. 최근 공공 영역에서도 AI 챗봇, 민원 자동응답, 내부 지식 검색, 행정업무 자동화 같은 표현이 자주 등장하고 있습니다. 그런데 실제로 AI가 행정업무를 도우려면 먼저 해결해야 할 문제가 있습니다. 바로 AI가 읽을 수 있는 문서가 충분히 존재하느냐는 문제입니다.
행정안전부는 2026년 5월 12일 보도자료를 통해 「행정업무 운영 및 혁신에 관한 규정」 개정안이 국무회의에서 의결됐다고 밝혔습니다. 핵심은 행정기관이 전자문서를 작성할 때 AI 활용을 고려하고, 개방형 문서 형식을 준수하도록 하는 것입니다.
이 변화는 얼핏 보면 “앞으로 문서를 어떤 파일 형식으로 저장할 것인가”의 문제처럼 보입니다. 하지만 조금 더 깊게 보면 공공 AI 도입의 기반을 바꾸는 정책입니다. AI 모델이 아무리 좋아도, 행정문서가 이미지처럼 굳어 있거나, 내부 구조를 알 수 없거나, 검색과 추출이 어려운 형태라면 자동화 품질은 제한될 수밖에 없습니다.
이 글에서는 이번 개정의 의미를 단순 제도 변경이 아니라 AI-ready government documents, 즉 AI가 활용할 수 있는 행정문서 체계로 전환하는 출발점으로 해석해 보겠습니다. 다만 “AI 정부”라는 표현은 정부가 공식적으로 선언한 정책 슬로건이 아니라, 이 글에서 공공 AI 전환의 방향을 설명하기 위해 사용하는 분석적 표현입니다.
개방형 문서 형식이란 무엇인가
개방형 문서 형식은 단순히 “무료 프로그램으로 열 수 있는 파일”이라는 뜻이 아닙니다. 행정안전부 보도자료는 개방형 문서 형식을 “기술 표준과 규격이 공개되어, AI와 사람이 모두 쉽게 읽고 활용할 수 있는 기계판독 가능 형태”로 설명합니다. 여기서 중요한 단어는 공개된 규격, 기계 판독, 활용 가능성입니다.
현행 「행정업무의 운영 및 혁신에 관한 규정」의 제3조 정의 조항에서도 개방형 문서 형식은 기술 표준과 규격이 공개되어 있고, 「공공데이터의 제공 및 이용 활성화에 관한 법률」상 기계 판독이 가능한 형태의 요건을 갖춘 전자문서 형식으로 정의됩니다. 「공공데이터법」 제2조 제3호는 기계 판독 가능성을 소프트웨어가 데이터의 개별 내용이나 내부 구조를 확인하고, 수정·변환·추출 등 처리할 수 있는 상태로 설명합니다.
쉽게 말하면 사람이 눈으로 읽는 데서 끝나는 문서가 아니라, 컴퓨터가 문서의 구조를 이해하고 필요한 정보를 꺼낼 수 있어야 합니다. 제목, 본문, 표, 주석, 첨부, 작성일, 기관명, 담당 부서, 키워드 같은 요소가 기계적으로 식별 가능해야 합니다. 그래야 검색, 요약, 분류, 번역, 민원 응답, 내부 지식 검색 같은 AI 활용이 안정적으로 이어질 수 있습니다.
따라서 개방형 문서 형식은 “파일 확장자 하나를 바꾸는 일”이 아닙니다. 행정문서를 데이터 인프라로 다루겠다는 관점의 변화에 가깝습니다. 문서가 닫힌 파일에서 끝나지 않고, 공공데이터·업무 시스템·AI 서비스가 재활용할 수 있는 구조적 자산이 되는 것입니다.
2026년 5월 12일 발표에서 실제로 바뀐 것
이번 발표에서 가장 눈에 띄는 대목은 전자문서 작성 단계부터 AI 활용을 고려하도록 한 점입니다. 행정안전부는 보도자료에서 행정기관 문서가 개방형으로 작성되지 않아 AI 활용에 한계가 있다는 지적 등을 반영해 개정을 추진했다고 설명했습니다. 이는 AI 도입을 응용 서비스 단계가 아니라 문서 생산 단계에서부터 다루겠다는 신호로 읽을 수 있습니다.
또 하나 중요한 내용은 적용 범위입니다. 보도자료에 따르면 행정안전부는 중앙정부 및 지방정부와의 협의를 거쳐 2026년 5월 18일부터 중앙·지방 온나라 문서시스템에 개방형 문서만 첨부하도록 의무화한다고 밝혔습니다. 이 글 작성 시점인 2026년 5월 13일 기준으로는 아직 적용일 전이므로, “시행됐다”보다는 “2026년 5월 18일부터 적용 예정”이라고 쓰는 것이 더 정확합니다.
온나라 문서시스템은 행정기관의 문서 작성·결재·유통과 관련된 핵심 업무 시스템입니다. 행정안전부의 과거 공식 설명 자료를 보면 온나라 문서시스템은 중앙행정기관과 지방자치단체의 업무관리·문서처리 기반으로 설명되어 왔습니다. 따라서 이 시스템에서 개방형 문서 첨부를 의무화한다는 것은 단순 권고보다 실무 영향이 클 수 있습니다.
함께 발표된 내용도 있습니다. 행정안전부는 외국어 번역본 제공 노력 규정을 신설하고, 행정업무 혁신 기여자에 대한 보상 체계를 개선한다고 설명했습니다. 기존에는 소속 공무원 중심의 특별성과포상금 제도가 강조됐다면, 개정 내용은 성과 창출에 함께 기여한 소속 직원과 파견 직원까지 포상 범위를 넓히는 방향입니다. 다만 이 글의 중심은 이 부가 조항보다 “AI가 읽을 수 있는 행정문서”에 있습니다.
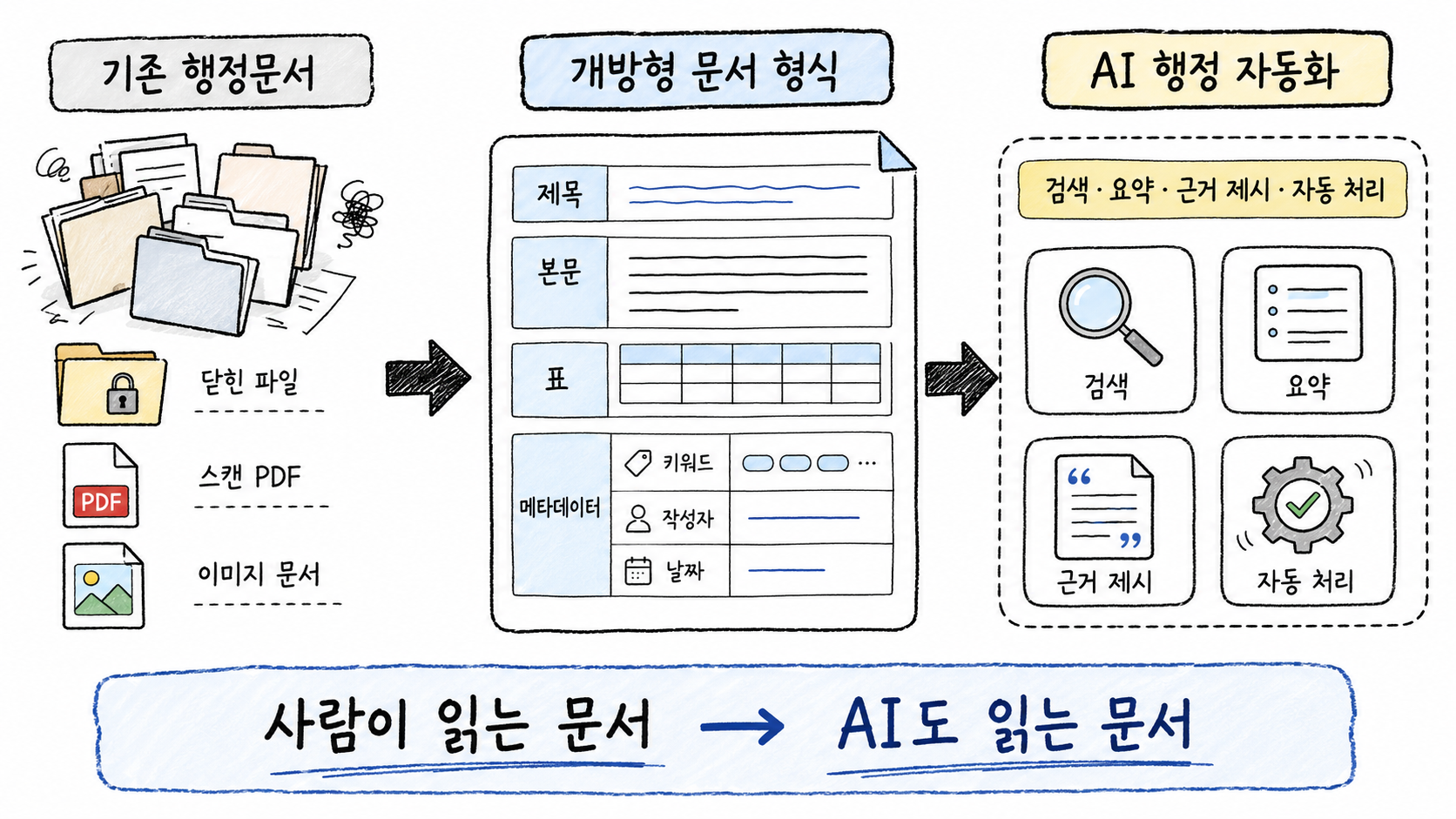
AI 행정 자동화를 가능하게 하는 개방형 문서 형식 흐름도
왜 문서 형식이 공공 AI의 첫 단추인가
공공 AI 논의는 흔히 챗봇 화면에서 시작합니다. 민원인이 질문을 입력하면 AI가 답하고, 공무원이 내부 지식을 검색하면 관련 규정과 사례를 요약해 주는 모습을 떠올리기 쉽습니다. 하지만 그 앞단에는 반드시 문서가 있습니다. AI가 답하려면 읽을 수 있는 규정, 지침, 회의자료, 공문, 보고서, 통계표, 첨부자료가 있어야 합니다.
문제가 되는 것은 많은 행정문서가 사람의 눈으로 읽는 데 맞춰져 있었다는 점입니다. 스캔 이미지로 된 PDF, 표 구조가 깨진 문서, 메타데이터가 빠진 파일, 시스템마다 다르게 저장되는 첨부파일은 사람이 일일이 열어보면 이해할 수 있을지 몰라도 AI가 안정적으로 처리하기에는 부담이 큽니다. 특히 근거를 제시해야 하는 행정 업무에서는 “대충 비슷한 답”이 아니라 “어느 문서의 어느 조항에 근거한 답인지”가 중요합니다.
그래서 개방형 문서 형식 의무화는 공공 AI의 하부 구조를 정비하는 일입니다. AI 행정 자동화의 핵심은 모델을 구매하는 것만이 아닙니다. 문서 구조를 정비하고, 검색 가능한 상태로 만들고, 메타데이터를 붙이고, 기관 간 호환성을 높이고, 장애인과 외국인도 접근 가능한 문서 체계를 갖추는 일이 함께 필요합니다.
이 관점에서 보면 이번 정책은 “AI 챗봇을 만들겠다”는 발표보다 더 기초적인 변화입니다. 챗봇은 사용자에게 보이는 화면이지만, 문서 형식은 챗봇이 읽는 지식의 토양입니다. 토양이 부실하면 어떤 AI 모델을 올려도 행정 자동화의 정확성과 신뢰성은 제한될 수밖에 없습니다.
RAG 관점에서 보는 행정문서 품질 문제
최근 공공기관과 기업에서 많이 검토하는 방식이 RAG입니다. RAG는 Retrieval-Augmented Generation의 줄임말로, 대형언어모델이 자체 기억만으로 답하는 것이 아니라 외부 지식 저장소에서 관련 문서를 검색한 뒤 그 내용을 바탕으로 답변을 생성하는 방식입니다. AWS는 RAG 설명 자료에서 외부 지식 기반을 참조해 LLM 출력을 최적화하는 방식으로 설명하고, Microsoft Azure AI Search도 RAG 개요에서 응답을 보유 콘텐츠에 근거시키는 접근으로 설명합니다.
RAG에서 중요한 것은 모델만이 아닙니다. 문서를 어떻게 쪼개고, 어떤 메타데이터를 붙이고, 어떤 구조로 검색 인덱스를 만들었는지가 답변 품질에 큰 영향을 줍니다. Microsoft의 문서 청킹 관련 설명도 RAG 성능에서 텍스트 청킹 전략이 중요하며, 문서 구조·제목·문단 같은 정보를 활용할 수 있음을 보여줍니다.
행정문서에 이를 적용하면 문제가 더 분명해집니다. 예를 들어 공문이 스캔 이미지 PDF로만 저장되어 있다면 먼저 OCR을 거쳐야 합니다. OCR 과정에서 글자가 잘못 인식되거나 표 구조가 깨지면, AI는 잘못된 근거를 검색할 수 있습니다. 폐쇄형 문서나 비정형 파일이 많으면 문서 안의 제목, 조항, 표, 주석, 첨부 관계를 안정적으로 추출하기 어렵습니다.
반대로 개방형 문서 형식과 잘 정리된 메타데이터가 결합되면 RAG 품질은 좋아질 가능성이 큽니다. 문서의 제목과 본문 구조를 인식하고, 조항 단위로 검색하고, 표 데이터를 별도로 추출하고, 작성 기관과 날짜를 기준으로 최신성을 판단할 수 있기 때문입니다. 결국 AI 행정서비스의 품질은 “어떤 모델을 쓰느냐”와 함께 “어떤 문서를 먹이느냐”에 달려 있습니다.
RAG 품질이 문서 구조화와 메타데이터에 따라 달라지는 과정
기존 행정문서와 AI-ready 문서의 차이
이번 개방형 문서 형식 의무화는 기존 행정문서를 AI가 활용 가능한 문서로 바꾸기 위한 출발점으로 볼 수 있습니다. 아래 표는 이를 실무 관점에서 정리한 것입니다.
| 구분 | 기존 폐쇄형·비정형 문서 중심 행정 | 개방형·기계판독형 문서 기반 행정 | 실무적 의미 |
|---|---|---|---|
| 문서의 기본 역할 | 사람이 열람하고 결재·보관하는 파일 | 사람과 AI가 함께 읽고 재활용하는 데이터 자산 | 문서가 업무 기록을 넘어 자동화 입력값이 됨 |
| 구조 인식 | 제목, 표, 문단, 첨부 관계가 파일마다 다르게 처리될 수 있음 | 공개된 규격과 구조를 바탕으로 소프트웨어가 내부 구조를 해석 가능 | 검색·분류·요약 품질 개선 가능 |
| RAG 활용성 | 스캔 PDF, 이미지 문서, 깨진 표가 많을수록 검색과 근거 추출이 어려움 | 문단·조항·표·메타데이터 단위로 인덱싱하기 쉬움 | 근거 기반 답변과 감사 추적에 유리 |
| 기관 간 호환성 | 시스템·문서 도구·저장 방식에 따라 재사용 비용 발생 | 공개 표준을 바탕으로 변환과 연계 부담 감소 가능 | 중앙·지방·산하기관 간 협업 기반 강화 |
| 접근성 | 이미지 중심 문서는 보조기기와 자동 번역에 불리할 수 있음 | 텍스트와 구조 정보가 보존되면 접근성과 번역 가능성 향상 | 외국어 번역본 제공, 정보 접근권과도 연결 |
| 파일 형식 이슈 | 특정 파일 형식에 대한 의존이 커질 수 있음 | 공개 규격과 기계 판독 가능성이 핵심 기준 | HWPX, PDF, DOCX 등 세부 허용 여부는 추가 확인 필요 |
| 정책 성격 | 문서 관리 규정 또는 업무 편의 문제로 인식 | 공공 AI·공공데이터·행정 자동화 인프라 문제로 확장 | 정보화 부서뿐 아니라 정책·기록·데이터 부서 협업 필요 |
이 표에서 특히 중요한 것은 마지막 행입니다. 이번 정책은 정보화 담당 부서만의 일이 아닙니다. 문서를 작성하는 정책 부서, 기록물을 관리하는 부서, 공공데이터를 개방하는 부서, AI 서비스를 기획하는 부서가 모두 연결됩니다. 문서 작성 방식이 바뀌지 않으면 AI 서비스 기획도 반복적으로 데이터 정제 비용에 부딪힐 수 있습니다.
또한 파일 형식 논의에서 주의할 점이 있습니다. 공개 자료 기준으로 이번 보도자료는 개방형 문서 형식이라는 원칙과 온나라 문서시스템 적용 일정을 강조하지만, HWPX, PDF, DOCX 등 구체 확장자별 허용 목록을 본문에서 상세히 단정하기는 어렵습니다. 따라서 실무 적용 단계에서는 행정안전부 첨부자료, 최종 개정 조문, 온나라 문서시스템 운영 안내를 함께 확인해야 합니다.
아직 확인해야 할 한계와 실무 쟁점
첫 번째 쟁점은 구체 파일 형식과 예외 기준입니다. HWPX처럼 공개 규격을 지향하는 형식, 텍스트 기반 PDF, 이미지 PDF, DOCX 등은 실제 업무에서 서로 다른 처리 특성을 가집니다. 하지만 “어떤 확장자가 무조건 허용된다”거나 “어떤 형식은 전면 금지된다”고 말하려면 최종 법령 조문과 운영 지침 확인이 필요합니다.
두 번째 쟁점은 기존 문서의 전환 문제입니다. 2026년 5월 18일부터 온나라 문서시스템 첨부 단계에서 개방형 문서만 요구하더라도, 이미 축적된 과거 문서가 모두 AI-ready 상태로 바뀌는 것은 아닙니다. 과거 스캔 문서, 이미지 PDF, 구조가 깨진 표, 오래된 폐쇄형 파일은 별도의 변환·정제·검수 과정이 필요할 수 있습니다.
세 번째 쟁점은 메타데이터 표준입니다. 문서가 개방형 형식이어도 제목, 작성 기관, 담당 부서, 생산일, 보존 기간, 공개 여부, 개인정보 포함 여부 같은 메타데이터가 부실하면 AI 활용은 제한됩니다. 공공데이터포털의 공공데이터 제공 표준처럼 데이터 항목과 제공 형식을 표준화하려는 흐름과도 연결해 볼 필요가 있습니다.
네 번째 쟁점은 보안과 개인정보입니다. 행정문서를 AI가 읽기 쉬운 형태로 만든다는 것은 활용 가능성을 높인다는 뜻이지만, 동시에 접근 통제와 민감정보 관리도 더 정교해져야 한다는 뜻입니다. 어떤 문서는 내부 검색에는 활용할 수 있지만 외부 공개나 AI 학습에는 사용할 수 없을 수 있습니다. 따라서 문서 형식 표준화는 권한 관리, 비식별 처리, 감사 로그와 함께 설계되어야 합니다.
다섯 번째 쟁점은 실제 작성자의 업무 부담입니다. 문서 형식만 바꾸면 끝나는 것이 아니라, 작성자가 표를 어떻게 만들고, 제목 체계를 어떻게 쓰고, 첨부파일을 어떤 기준으로 붙이고, 요약과 키워드를 어떻게 입력할지까지 바뀔 수 있습니다. 개방형 문서 형식 의무화가 현장에서 작동하려면 문서 작성 도구, 교육, 자동 검증 기능, 예외 처리 절차가 함께 필요합니다.
정책 담당자와 GovTech 기업이 봐야 할 시사점
정책 담당자에게 이번 이슈는 AI 도입 사업을 평가하는 기준을 바꿔야 한다는 신호입니다. 앞으로 공공 AI 사업을 검토할 때 “어떤 LLM을 쓸 것인가”만 물어서는 부족합니다. “어떤 문서를 어떤 구조로 수집할 것인가”, “문서의 최신성과 권한을 어떻게 관리할 것인가”, “근거 문서를 어떻게 추적할 것인가”를 함께 물어야 합니다.
IT 기획자에게는 문서 시스템과 AI 시스템을 분리해서 보면 안 된다는 메시지입니다. 온나라 문서시스템, 기록관리시스템, 공공데이터 제공 시스템, 내부 지식 검색 시스템, 민원 AI 챗봇은 모두 문서를 매개로 연결됩니다. 문서가 구조화되어 있지 않으면 각 시스템은 별도의 정제 파이프라인을 만들게 되고, 이는 비용과 오류를 키울 수 있습니다.
GovTech 스타트업에게도 중요한 변화입니다. 공공기관이 개방형 문서 형식을 본격적으로 요구하기 시작하면, 단순 챗봇 구축보다 문서 변환, 메타데이터 추출, 품질 검증, 접근성 점검, RAG 인덱싱, 기록관리 연계 같은 영역의 수요가 커질 수 있습니다. 특히 행정문서 특유의 결재 구조, 첨부 관계, 공개·비공개 구분, 법령 근거 추적을 이해하는 솔루션이 더 중요해질 가능성이 있습니다.
다만 이 전망은 공개 자료를 바탕으로 한 분석입니다. 정부가 이번 발표에서 “한국형 AI 행정 자동화의 시작점”이라고 직접 선언한 것은 아닙니다. 이 표현은 개방형 문서 형식 의무화가 AI 행정 자동화의 기반 인프라를 건드린다는 점에서 붙일 수 있는 해석적 표현입니다.
온나라 문서시스템에서 개방형 문서가 행정 데이터 인프라로 전환되는 구조
이 이슈에서 얻을 수 있는 관찰 기준
이번 개방형 문서 형식 의무화는 앞으로 AI 정책을 볼 때 어떤 질문을 던져야 하는지 알려줍니다. 첫째, AI 서비스의 화면보다 입력 데이터의 품질을 먼저 봐야 합니다. 챗봇이 멋지게 보이더라도, 그 뒤의 문서가 낡고 비정형적이면 실제 답변 품질은 흔들릴 수 있습니다.
둘째, 표준은 눈에 잘 띄지 않지만 가장 오래가는 인프라입니다. 모델은 바뀔 수 있고, 서비스 UI도 바뀔 수 있습니다. 그러나 문서 표준과 메타데이터 체계는 한 번 잘 만들어지면 여러 AI 서비스와 행정 시스템이 계속 재사용할 수 있습니다.
셋째, 공공 AI는 정확성뿐 아니라 설명 가능성과 책임성이 중요합니다. 행정 답변은 “그럴듯함”으로 끝나면 안 됩니다. 어떤 문서, 어떤 조항, 어떤 날짜의 자료를 근거로 했는지 추적할 수 있어야 합니다. 기계가 읽을 수 있는 문서 구조는 바로 이 근거 추적의 출발점입니다.
넷째, AI 도입은 기술 도입이면서 동시에 업무 방식 개편입니다. 문서 작성자가 구조화된 문서를 만들고, 시스템이 이를 검증하며, AI가 이를 검색하고, 사용자가 근거를 확인하는 흐름이 만들어져야 합니다. 이 연결이 끊기면 AI는 시범사업에서는 작동해도 실제 행정 현장에서는 확장되기 어렵습니다.
결론
이번 행정안전부 발표를 한 문장으로 정리하면, 공공 AI 도입의 출발점이 화면에 보이는 챗봇이 아니라 행정문서의 형식과 구조로 이동하고 있다는 것입니다. AI가 행정문서를 제대로 읽으려면 문서가 개방형이어야 하고, 기계 판독 가능해야 하며, 검색과 추출과 재활용이 가능해야 합니다.
개방형 문서 형식 의무화는 단순한 문서 저장 방식 변경이 아닙니다. 행정문서를 AI가 활용할 수 있는 공공 데이터 자산으로 바꾸는 기반 작업입니다. 특히 RAG 기반 지식 검색, 민원 응답, 내부 업무 자동화, 외국어 번역본 제공, 공공데이터 재활용까지 생각하면 문서 형식은 공공 AI 품질의 출발선이 됩니다.
물론 아직 확인해야 할 부분도 있습니다. HWPX, PDF, DOCX 등 구체 형식별 허용 여부, 예외 처리, 과거 문서 전환, 보안과 개인정보 관리, 온나라 문서시스템의 실제 적용 방식은 최종 법령과 운영 지침을 통해 더 확인해야 합니다. 따라서 이 글의 핵심은 “모든 문제가 해결됐다”가 아니라 “AI 행정을 가능하게 하는 가장 기초적인 인프라 변화가 시작됐다”에 가깝습니다.
이번 주제는 어떠셨나요? 저는 이번 개방형 문서 형식 의무화가 공공 AI 논의의 초점을 더 현실적인 곳으로 옮기는 계기가 될 수 있다고 봅니다. AI 정부를 만들고 싶다면 먼저 AI가 읽을 수 있는 행정문서를 만들어야 합니다. 긴 글 읽어주셔서 감사합니다.