핵심 요약
- 풀스택 개발자의 AI 도구 활용은 단순 코드 자동완성에서 “작업 단위 전체를 맡기는 에이전트형 워크플로”로 이동하고 있습니다.
- Cursor는 코드베이스, 멀티레포, 클라우드 개발 환경, PR 리뷰에 강점이 있고, Perplexity Computer는 리서치·문서·웹 게시·업무 워크플로에 강점이 있습니다.
- Gemini API는 개발자가 직접 제품에 붙일 수 있는 RAG, 멀티모달 File Search, Webhooks, Deep Research Agent 같은 인프라성 기능에 초점이 맞춰져 있습니다.
- 핵심은 AI 도구 하나를 고르는 것이 아니라, 기획/조사 → 코드 수정 → 테스트·리뷰 → RAG → 배포·공유 → 보안 점검의 단계별 병목을 어떻게 나눠 맡길지 설계하는 것입니다.
- 클라우드 에이전트가 강력해질수록 리뷰, 승인, secrets 관리, egress 통제, 감사 로그, prompt injection 검토 같은 운영 체계가 더 중요해집니다.
목차
풀스택 개발자의 병목은 코드 작성만이 아닙니다
안녕하세요? 오늘 다룰 주제는 풀스택 개발자의 AI 개발 워크플로 변화입니다. 최근 AI 코딩 도구를 보면 단순히 “다음 줄 코드를 잘 추천하는가”보다 “개발자가 하려는 작업 전체를 얼마나 끝까지 이어갈 수 있는가”가 더 중요한 기준이 되고 있습니다.
풀스택 개발자는 프론트엔드, 백엔드, DB, 인프라, 배포, 보안, 문서화까지 함께 봐야 합니다. 그래서 실제 병목은 코드 한 줄을 빨리 쓰는 데만 있지 않습니다. 요구사항을 이해하고, 관련 레포를 찾고, API 계약을 맞추고, 테스트를 돌리고, PR을 나누고, 배포 가능한 산출물로 공유하는 전 과정에서 시간이 새어 나갑니다.
이번 글에서는 Cursor, Perplexity Computer, Gemini API 업데이트를 하나의 흐름으로 묶어 보겠습니다. 관점은 “어떤 도구가 더 좋은가”가 아니라, 풀스택 개발자가 개발 단계별 병목을 어떻게 나눠서 자동화할 수 있는가입니다.
작성 시점은 2026년 5월 17일입니다. 기능명, 출시일, 가격, preview 여부는 공식 문서 기준으로 확인했지만, AI 개발 도구는 업데이트 주기가 매우 빠르기 때문에 실제 도입 전에는 각 서비스의 최신 요금제와 정책을 다시 확인하는 것이 좋습니다.
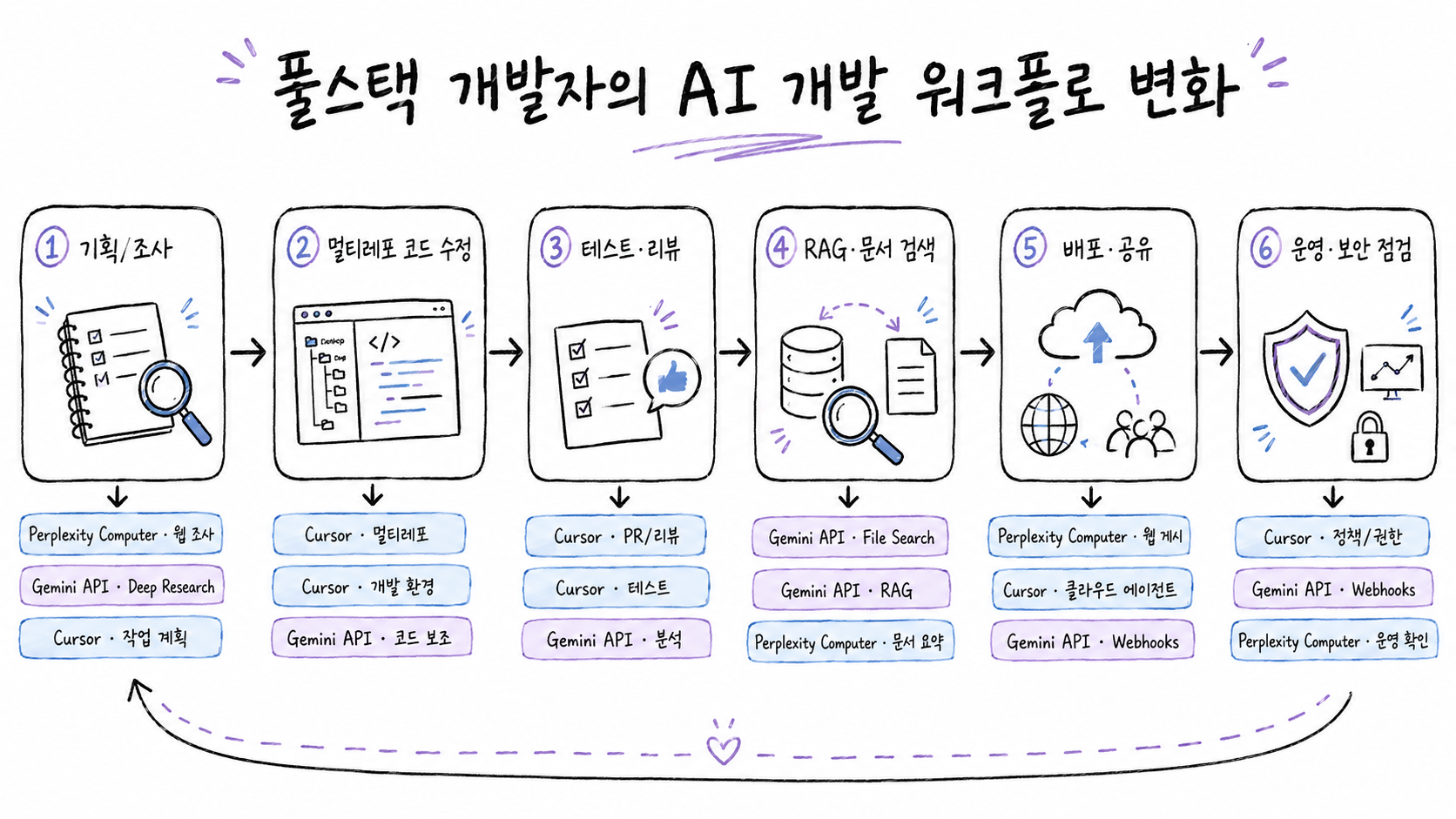
풀스택 개발자의 AI 개발 워크플로 변화 개념도
Cursor는 개발 환경과 멀티레포 작업을 에이전트에게 열어준다
Cursor의 2026년 5월 13일 changelog에서 가장 눈에 띄는 부분은 “cloud agents를 위한 development environments”입니다. Cursor는 클라우드 에이전트가 작업을 처음부터 끝까지 수행하려면 로컬 노트북과 비슷한 환경, 즉 cloned repositories, installed dependencies, internal toolchain credentials, build systems 접근이 필요하다고 설명합니다.
이 변화가 풀스택 팀에 중요한 이유는 명확합니다. 대규모 서비스에서는 프론트엔드, 백엔드, 인프라, 공통 패키지, 디자인 시스템 레포가 나뉘어 있는 경우가 많습니다. Cursor는 cloud agents와 automations가 이제 multi-repo environments를 지원한다고 밝혔고, 하나의 환경에 에이전트가 작업에 필요한 여러 레포를 구성해 세션 간 재사용할 수 있다고 설명했습니다.
예를 들어 결제 페이지의 프론트엔드 UI를 수정하면서 백엔드 API 응답 스키마, DB migration, Terraform 설정, 문서까지 함께 바꿔야 한다고 가정해 보겠습니다. 단일 레포만 보는 에이전트는 프론트엔드 컴포넌트는 고칠 수 있어도 API 계약이나 배포 설정까지 함께 추론하기 어렵습니다. 반면 멀티레포 환경에서는 “이 변경이 다른 레포에 어떤 영향을 주는가”를 더 넓은 맥락에서 다룰 수 있습니다.
Cursor의 Dockerfile 기반 환경 설정 강화도 실무적으로 중요합니다. 공식 발표에 따르면 Cursor는 Dockerfile 기반 configuration을 개선했고, private package registry에 접근하기 위한 build secrets를 지원합니다. 또한 build secrets는 build step에만 scope가 걸리고 running agent environment로 전달되지 않는다고 설명했습니다.
이는 풀스택 팀의 보안 설계와 직접 연결됩니다. 에이전트가 테스트를 돌리려면 패키지 레지스트리, 내부 API, staging DB, 빌드 시스템에 접근해야 할 수 있습니다. 하지만 모든 secret을 한꺼번에 열어주는 방식은 위험합니다. 그래서 secrets scope, egress allowlist, audit log 같은 통제 장치가 AI 개발 워크플로의 핵심 인프라가 됩니다.
Cursor는 같은 발표에서 layer caching도 개선했다고 밝혔습니다. Dockerfile이 변경될 때 업데이트된 레이어만 재빌드되며, 캐시가 적중한 빌드는 70% 더 빠르다고 설명했습니다. 이 수치는 Cursor 공식 발표 기준입니다.
이 기능은 단순한 속도 개선처럼 보이지만, 풀스택 개발자에게는 꽤 현실적인 의미가 있습니다. AI 에이전트가 코드를 작성한 뒤 테스트를 돌리려면 환경이 매번 안정적으로 만들어져야 합니다. 환경 빌드가 느리거나 자주 깨지면 개발자는 결국 “AI에게 맡기는 시간”보다 “환경 문제를 다시 설명하는 시간”을 더 많이 쓰게 됩니다.
Cursor의 2026년 5월 7일 changelog도 연결해서 볼 필요가 있습니다. 해당 업데이트에는 PR review 경험, plan을 병렬로 실행하는 Build in Parallel, 변경사항을 논리적으로 나눠 여러 PR로 분리하는 기능이 포함되어 있습니다. Cursor는 독립적인 부분은 async subagents로 동시에 실행하고, 의존성이 있는 단계는 순서를 유지한다고 설명했습니다.
다만 여기서 중요한 것은 “완전 자동 개발”이 아닙니다. 오히려 Cursor의 흐름은 에이전트가 더 많은 작업을 하게 만들수록, 개발자가 리뷰하고 승인할 수 있는 구조가 더 중요해진다는 점을 보여줍니다. 변경사항을 PR 단위로 나누고, 테스트 결과를 확인하고, 보안상 민감한 변경은 사람이 승인해야 합니다.
실제 개발자 반응에서도 이 지점이 드러납니다. 한 Cursor 커뮤니티 사용자는 멀티레포 맥락이 프론트엔드와 백엔드 관계를 이해하는 데 중요하다고 보면서도, 실제 병목은 에이전트를 기다리는 시간이 아니라 결과를 리뷰하고 테스트하는 시간이라고 적었습니다. 이는 공식 기능이 아니라 커뮤니티 사례 수준의 의견이지만, 풀스택 팀이 도입 시 반드시 고려해야 할 현실적인 포인트입니다.
Perplexity Computer는 조사에서 웹 게시까지 업무 산출물을 만든다
Perplexity Computer의 2026년 5월 4일 changelog는 Cursor와는 다른 방향의 변화를 보여줍니다. Cursor가 코드베이스와 개발 환경에 초점을 둔다면, Perplexity Computer는 리서치, 문서, 데이터 분석, 웹사이트 구축, 업무 워크플로 자동화에 더 가깝습니다.
Perplexity는 해당 changelog에서 GPT-5.5가 Computer의 default orchestration model로 Pro와 Max subscribers에게 rolling out 중이라고 밝혔습니다. 또 GPT Image 2가 Computer의 image generation과 image-editing flows의 기본 모델이라고 설명했습니다. 이 부분은 Perplexity 발표 기준이며, OpenAI 공식 자료에서도 GPT-5.5 모델과 gpt-image-2 이미지 모델 자체는 확인됩니다.
다만 Perplexity Computer 내부에서 이 모델들이 어떤 범위와 조건으로 적용되는지, 어떤 요금제·지역·기업 설정에서 실제 사용 가능한지는 Perplexity의 최신 정책을 다시 확인해야 합니다. 모델명이 공식적으로 존재한다는 사실과, 특정 서비스 내부에서 어떤 식으로 라우팅되는지는 서로 다른 문제입니다.
Perplexity Computer의 기능 중 풀스택 개발자에게 흥미로운 것은 plan previews입니다. Perplexity는 긴 작업이나 credit-heavy task를 시작하기 전에 Computer가 structured plan을 작성하고 승인을 기다린다고 설명합니다. 이는 AI 에이전트가 무작정 작업을 시작하는 것이 아니라, 먼저 범위와 접근법을 확인받는 구조입니다.
풀스택 개발자의 기획/조사 단계에 이 기능을 연결해 볼 수 있습니다. 예를 들어 “경쟁사의 온보딩 플로우를 조사하고, 우리 서비스의 개선안을 정리한 뒤, 간단한 랜딩 페이지 프로토타입을 만들어줘”라고 요청한다고 가정해 보겠습니다. 이때 중요한 것은 처음부터 결과물을 생성하는 것이 아니라, 조사 범위, 비교 기준, 산출물 형식, 게시 여부를 먼저 합의하는 것입니다.
Perplexity는 같은 changelog에서 Computer가 웹사이트와 full-stack apps를 persistent, shareable *.pplx.app URL로 publish할 수 있다고 설명했습니다. 또한 hosting, deployment, DNS, backend infrastructure, environment variables를 별도로 설정하지 않고 preview 후 live site를 게시할 수 있다고 소개했습니다.
이 기능은 프로덕션 배포라기보다 기획과 프로토타입 공유에 더 적합하게 보는 것이 안전합니다. 예를 들어 PM, 디자이너, 개발 리드가 함께 보는 캠페인 페이지 초안, CSV 기반 내부 대시보드, 간단한 ROI 계산기 같은 산출물을 빠르게 공유하는 흐름입니다. 실제 고객-facing 서비스나 보안이 중요한 앱이라면 인증, 데이터 저장, 배포 제한, 장애 대응, 로그, 개인정보 처리까지 별도로 확인해야 합니다.
Perplexity의 inline file diff도 개발자 관점에서 의미가 있습니다. Computer가 파일을 편집하면 thread 안에서 + / – diff로 변경사항을 보여준다고 설명합니다. 이는 AI가 만든 문서, 웹페이지, 코드성 파일을 그대로 신뢰하지 않고, 변경된 내용을 사람이 검토할 수 있게 하는 장치입니다.
또한 Perplexity는 Microsoft Teams 앱, Snowflake·Databricks 연결, 시장조사·sales prep·slide creation·website audits·website building 같은 Workflows를 소개했습니다. 이 부분은 풀스택 개발자의 “코드 작성 전후 업무”와 맞닿아 있습니다. 리서치 문서, 요구사항 정리, 웹사이트 감사, 데이터 기반 보고서, 프로토타입 공유는 개발자가 직접 코딩하기 전에도 많은 시간을 쓰는 영역입니다.
따라서 Perplexity Computer는 Cursor의 대체재라기보다 앞단과 주변부를 맡는 도구로 보는 편이 정확합니다. Cursor가 “코드베이스 안에서 변경을 만들어 PR로 보내는 도구”라면, Perplexity Computer는 “조사하고, 정리하고, 업무 산출물을 만들고, 공유 가능한 형태로 게시하는 도구”에 가깝습니다.
Gemini API는 제품 안에 RAG와 리서치 인프라를 붙이는 도구다
Google Gemini API 업데이트는 조금 다른 층위에 있습니다. Cursor와 Perplexity가 개발자가 바로 사용하는 애플리케이션 성격이 강하다면, Gemini API는 개발자가 직접 제품과 내부 시스템에 붙이는 인프라에 가깝습니다.
Google은 2026년 5월 5일 Gemini API File Search의 multimodal search 지원을 changelog에 추가했습니다. 공식 changelog에 따르면 gemini-embedding-2 모델로 이미지를 native embed and search할 수 있고, grounding metadata에는 visual citation을 위한 media_id와 정보가 발견된 위치를 나타내는 page number가 포함됩니다.
File Search는 RAG, 즉 Retrieval Augmented Generation을 구현하는 도구입니다. 쉽게 말해 모델이 기억하고 있는 일반 지식만으로 답하게 하지 않고, 개발자가 넣어 둔 문서, 파일, 이미지, PDF 조각을 검색해 그 결과를 답변의 근거로 쓰게 하는 방식입니다.
공식 File Search 문서에 따르면 File Search는 데이터를 가져와 chunking, indexing을 수행하고, prompt에 맞는 관련 정보를 검색한 뒤 모델의 context로 사용합니다. 문서에는 text embedding은 gemini-embedding-001, image/multimodal embedding은 gemini-embedding-2가 지원된다고 설명되어 있습니다. 다만 같은 문서 기준으로 audio와 video formats는 현재 지원되지 않는다고 명시되어 있습니다.
여기서 풀스택 개발자가 볼 지점은 “사내 문서 검색”을 넘어섭니다. 예를 들어 제품 매뉴얼 PDF, 에러 스크린샷, 디자인 시안 이미지, 고객 문의 첨부파일, 운영 runbook을 하나의 검색 시스템으로 연결할 수 있습니다. 특히 media_id가 있으면 모델이 답변에 참고한 이미지 chunk를 다시 식별하거나 캐싱할 수 있어, 답변 검증과 UI 표시를 설계하기가 쉬워집니다.
Gemini Embedding 2 자체도 중요합니다. Google Developers Blog는 2026년 4월 30일 글에서 Gemini Embedding 2가 Gemini API에서 text, images, video, audio, documents를 하나의 embedding space로 매핑하는 첫 embedding model이며 100개 이상의 언어를 지원한다고 설명했습니다. 또한 한 번의 call에서 최대 8,192 text tokens, 6 images, 120 seconds video, 180 seconds audio, 6 pages PDFs를 처리할 수 있다고 밝혔습니다.
다만 앞서 말했듯, Embedding 2 모델의 입력 범위와 File Search 기능의 현재 지원 범위는 구분해야 합니다. Embedding 2는 멀티모달 임베딩 모델이고, File Search 문서는 현재 audio/video file formats가 지원되지 않는다고 설명합니다. 이런 차이를 무시하면 “Gemini File Search가 모든 미디어를 바로 검색한다”는 식의 과장된 표현이 되기 쉽습니다.
Gemini API의 Webhooks도 풀스택 앱 개발에 중요합니다. Google은 2026년 5월 4일 changelog에서 Gemini API의 event-driven Webhooks 지원을 발표했고, 공식 문서는 Webhooks가 asynchronous 또는 Long-Running Operations 완료 시 서버로 real-time notification을 push해 polling을 대체한다고 설명합니다.
이것은 AI 기능을 프로덕션 앱에 붙일 때 매우 현실적인 문제를 해결합니다. 긴 리서치 작업, Batch job, video generation, Interactions API 작업은 몇 초 안에 끝나지 않을 수 있습니다. 이때 프론트엔드가 계속 polling하거나 사용자가 대기하게 만드는 대신, 작업이 끝나면 webhook으로 결과 포인터를 받고, 내부 큐나 알림 시스템으로 넘길 수 있습니다.
Webhooks 문서에는 static webhooks와 dynamic webhooks가 나뉘어 있고, signing secret을 안전하게 저장해야 하며, 요청 서명을 검증해야 한다고 설명되어 있습니다. 또한 endpoint는 몇 초 안에 2xx 응답을 보내야 하고, 실패한 요청은 24시간 동안 exponential backoff로 retry된다고 설명합니다.
마지막으로 Deep Research Agent입니다. Gemini Deep Research Agent 문서에 따르면 이 에이전트는 multi-step research tasks를 autonomously plan, execute, synthesize하며, cited reports를 생성합니다. 하지만 현재 preview 상태이고, Interactions API에서만 사용할 수 있으며, generate_content로는 접근할 수 없습니다. 또한 연구 작업은 몇 분이 걸릴 수 있어 background=true로 비동기 실행해야 합니다.
풀스택 개발자 입장에서는 이 기능을 “리서치 기능을 내 제품 안에 넣는 API”로 볼 수 있습니다. 예를 들어 B2B SaaS의 고객 계정 분석, 경쟁사 리포트 생성, 내부 기술문서 조사, 장애 회고 자료 정리 같은 기능에 붙일 수 있습니다. 단, preview 기능이고 비용이 agentic workflow에 따라 변동될 수 있으므로, 초기에는 제한된 범위의 내부 도구부터 실험하는 것이 안전합니다.
실제 워크플로는 어떻게 재구성될까
이제 세 도구를 풀스택 개발자의 실제 흐름에 맞춰 배치해 보겠습니다. 핵심 순서는 기획/조사 → 멀티레포 코드 수정 → 테스트·리뷰 → RAG·문서 검색 → 배포·공유 → 운영·보안 점검입니다.
첫 단계는 기획/조사입니다. 여기서는 Perplexity Computer와 Gemini Deep Research Agent가 강점을 가질 수 있습니다. Perplexity Computer는 Workflows와 plan previews를 통해 시장조사, 웹사이트 감사, 슬라이드, 웹사이트 구축 같은 반복 업무를 구조화할 수 있고, Gemini Deep Research Agent는 제품 안에서 긴 리서치 작업을 수행하는 API 기반 선택지가 될 수 있습니다.
둘째 단계는 멀티레포 코드 수정입니다. 이 단계에서는 Cursor가 가장 직접적입니다. 프론트엔드 레포와 백엔드 레포, 인프라 레포가 나뉘어 있을 때 cloud agents가 multi-repo environment 안에서 필요한 레포를 함께 다루는 구조는 풀스택 개발자의 실제 환경과 잘 맞습니다.
셋째 단계는 테스트·리뷰입니다. Cursor의 Build in Parallel, PR review, split PRs는 작업을 빠르게 나누고 리뷰 가능한 단위로 만드는 데 초점이 있습니다. 하지만 테스트와 리뷰는 여전히 개발자의 병목으로 남습니다. AI 에이전트가 더 많은 변경을 만들수록, 사람이 검토할 수 있는 단위로 쪼개고, 실패한 테스트를 설명하고, 민감한 변경은 승인받는 체계가 필요합니다.
넷째 단계는 RAG·문서 검색입니다. Gemini API File Search는 제품 매뉴얼, 내부 runbook, 고객 문의 첨부파일, PDF, 이미지 기반 자료를 검색 가능한 형태로 만들 수 있습니다. 특히 grounding metadata, page number, media_id는 “AI가 어디를 근거로 답했는지”를 제품 UI에 표시하거나 검증 로그로 남기는 데 도움이 됩니다.
다섯째 단계는 배포·공유입니다. Perplexity Computer의 *.pplx.app publishing은 빠른 프로토타입 공유에 유용할 수 있습니다. 다만 이를 실제 운영 서비스 배포로 과장하면 안 됩니다. 인증, 데이터 저장, 배포 제한, 환경 변수, 장애 대응, 도메인, 감사 로그 같은 운영 조건은 별도로 확인해야 합니다.
여섯째 단계는 운영·보안 점검입니다. Cursor의 version history, rollback, audit log, egress 및 secrets scope는 클라우드 에이전트 운영에 필요한 통제 장치입니다. Gemini Webhooks의 signing secret, signature verification, replay protection은 AI 비동기 작업을 서버에 붙일 때 필요한 보안 장치입니다.
이렇게 보면 AI 개발 도구 도입은 “우리 팀은 Cursor를 쓸까, Perplexity를 쓸까, Gemini를 쓸까”의 문제가 아닙니다. 더 정확하게는 “어떤 단계의 병목을 어떤 도구에 맡기고, 어디서 사람이 승인하며, 어떤 로그와 보안 통제를 남길 것인가”의 문제입니다.
Cursor·Perplexity·Gemini API 역할 비교
아래 표는 세 도구를 풀스택 개발자의 업무 흐름 기준으로 구조화한 것입니다.
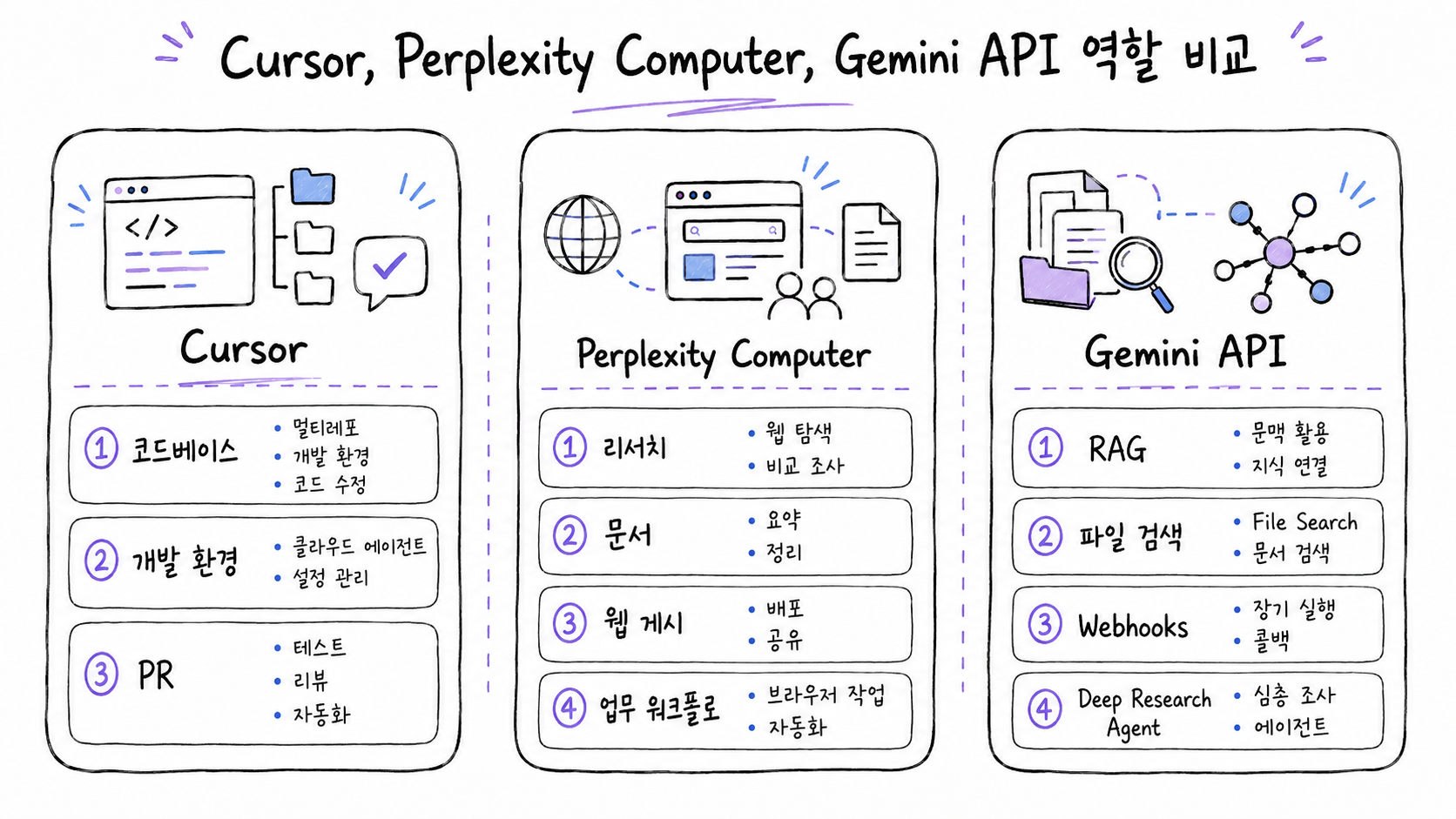
Cursor, Perplexity Computer, Gemini API 역할 비교
| 구분 | Cursor | Perplexity Computer | Gemini API |
|---|---|---|---|
| 중심 역할 | 코드베이스, 개발 환경, PR 중심 | 리서치, 문서, 웹 게시, 업무 워크플로 중심 | 제품에 붙이는 API, RAG, 에이전트 인프라 중심 |
| 잘 맞는 단계 | 멀티레포 코드 수정, 테스트 실행, PR 리뷰, 변경사항 분리 | 기획/조사, 시장조사, 슬라이드, 웹사이트 감사, 프로토타입 게시 | 사내/제품 내 파일 검색, 멀티모달 RAG, 비동기 작업 알림, 리서치 API |
| 핵심 업데이트 | cloud agent development environments, multi-repo, Dockerfile config, build secrets, audit log | plan preview, inline file diff, *.pplx.app publishing, Teams, Snowflake·Databricks, Workflows | File Search multimodal support, gemini-embedding-2, media_id, page number, Webhooks, Deep Research Agent |
| 풀스택 개발자에게 줄이는 병목 | 여러 레포를 넘나드는 코드 변경과 PR 정리 | 조사·문서화·공유용 산출물 제작 | 제품 안에서 근거 기반 검색·리서치·비동기 AI 작업 구현 |
| 주의할 점 | 에이전트 결과 리뷰, secret scope, egress, 테스트 승인 필요 | 실제 배포 제한, 요금제, Teams/connector 권한, 내부 모델 라우팅 확인 필요 | preview 여부, API 가격, File Search 제한, webhook 보안 검증 필요 |
Cursor는 개발자가 이미 가진 코드베이스를 더 잘 다루는 방향으로 진화하고 있습니다. 특히 멀티레포와 Dockerfile 기반 환경 설정은 풀스택 팀의 실제 개발 조건을 반영합니다.
Perplexity Computer는 개발 이전과 이후의 산출물을 다룹니다. 시장조사, 웹사이트 감사, 슬라이드, 웹 게시, Teams 대화 안에서의 자동화는 코드 자체보다 업무 흐름을 줄이는 기능입니다.
Gemini API는 사용자가 직접 쓰는 도구라기보다, 개발자가 제품 안에 AI 기능을 넣기 위한 재료입니다. File Search, Webhooks, Deep Research Agent는 “내 서비스 안에서 검색하고, 근거를 보여주고, 긴 작업을 비동기로 처리하는 AI 기능”을 만들 때 의미가 있습니다.
한계와 확인해야 할 부분
첫째, Cursor의 클라우드 에이전트는 강력하지만 환경 관리가 곧바로 쉬워지는 것은 아닙니다. 공식 포럼의 한 답변에서는 Dockerfile 변경 후 최신 환경으로 강제 rebuild하는 UI 버튼이 아직 없고, 저장된 환경을 삭제한 뒤 다시 만드는 workaround가 안내된 사례가 있습니다. 이는 특정 사용자 사례이지만, 클라우드 개발 환경이 실제 운영에서 “한 번 설정하면 끝”이 아니라는 점을 보여줍니다.
둘째, Perplexity Computer의 웹 게시 기능은 빠른 공유에는 매력적이지만, 프로덕션 앱 배포와 동일하게 보면 위험합니다. *.pplx.app publishing은 공식 changelog에 소개되어 있지만, 인증, 데이터 보관, 서버 리소스, 환경 변수, 사용자별 접근 제어, 로그, 장애 대응 같은 실제 운영 조건은 별도 확인이 필요합니다.
셋째, Perplexity가 언급한 GPT-5.5와 GPT Image 2는 OpenAI 공식 자료에서도 모델 자체가 확인됩니다. OpenAI API 문서에는 GPT-5.5 모델 페이지와 GPT Image 2 모델 페이지가 존재합니다. 다만 Perplexity Computer 안에서 어떤 요청이 어떤 모델로 처리되는지, 어떤 요금제와 credit 정책이 적용되는지는 Perplexity 발표와 최신 계정 설정 기준으로 확인해야 합니다.
넷째, Gemini API File Search는 멀티모달 RAG 관점에서 의미가 크지만, 모든 미디어 타입을 File Search에서 바로 지원한다는 뜻은 아닙니다. 공식 문서 기준으로 File Search는 image/multimodal embedding에 gemini-embedding-2를 사용할 수 있지만, audio와 video formats는 현재 지원되지 않습니다.
다섯째, Gemini Deep Research Agent는 preview입니다. 공식 문서는 Interactions API에서만 접근 가능하며 generate_content로는 사용할 수 없고, long-running research task는 background execution이 필요하다고 설명합니다. 비용도 일반적인 단일 모델 호출이 아니라 planning, searching, reading, reasoning loop를 포함하는 agentic workflow 기준으로 계산됩니다. 문서의 비용 추정치도 preview rates 기준이며 변경될 수 있다고 명시되어 있습니다.
여섯째, AI 에이전트에 사내 파일과 웹 접근을 함께 허용하면 prompt injection과 data exfiltration 위험이 커집니다. Gemini Deep Research Agent 문서도 업로드한 파일의 숨겨진 텍스트가 에이전트 출력을 조작할 수 있고, 민감한 내부 데이터를 웹 브라우징과 함께 요약하게 할 때 주의해야 한다고 설명합니다.
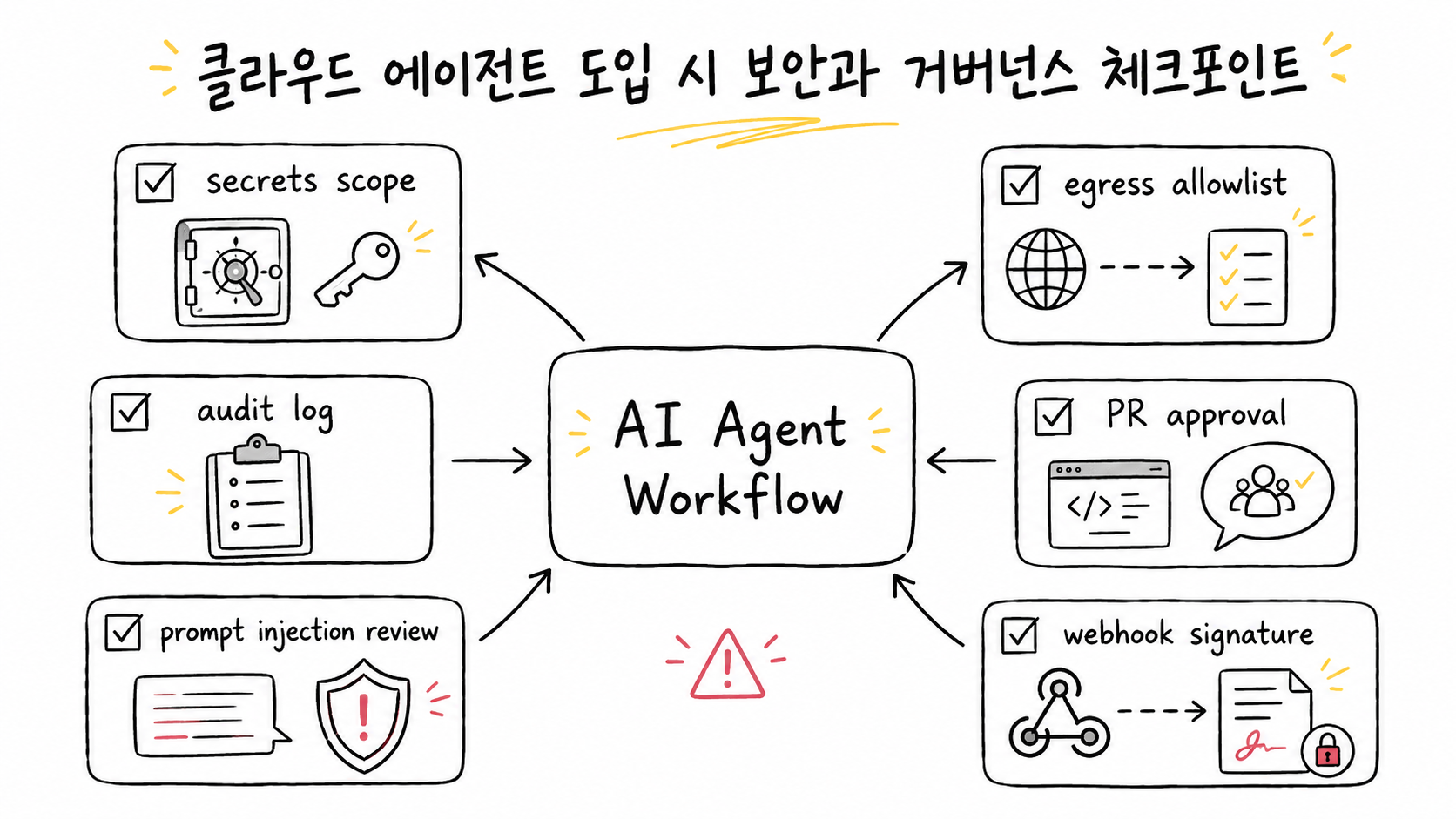
클라우드 에이전트 도입 시 보안과 거버넌스 체크포인트
따라서 이 글의 결론은 “AI 에이전트에게 더 많이 맡기자”가 아닙니다. 오히려 맡기는 범위가 넓어질수록 승인선, 로그, 권한, 테스트, 보안 정책을 더 명확히 설계해야 한다는 쪽에 가깝습니다.
풀스택 팀이 얻을 수 있는 시사점
풀스택 개발자와 개발 리드가 이 흐름에서 가장 먼저 봐야 할 것은 도구의 이름이 아니라 업무 단위입니다. 지금 팀에서 가장 큰 병목이 요구사항 조사인지, 멀티레포 변경인지, 테스트와 리뷰인지, 문서 검색인지, 배포 공유인지부터 나눠야 합니다.
예를 들어 프론트엔드와 백엔드 레포가 자주 함께 바뀌는 팀이라면 Cursor의 multi-repo environment와 PR 분리 흐름이 먼저 체감될 수 있습니다. 반대로 개발 전 기획 자료, 경쟁사 조사, 웹사이트 감사, 슬라이드, 내부 공유 페이지가 병목인 팀이라면 Perplexity Computer의 Workflows와 publishing 기능이 더 직접적일 수 있습니다.
이미 자체 SaaS를 운영하고 있고 고객-facing AI 기능을 붙이려는 팀이라면 Gemini API가 더 중요합니다. File Search로 제품 문서와 이미지 자료를 검색하게 하고, Webhooks로 긴 작업을 비동기 처리하고, Deep Research Agent를 제한된 내부 리서치 기능으로 실험할 수 있습니다.
개발 리드 관점에서는 “AI가 코드를 잘 짜는가”보다 “AI가 만든 변경을 우리 팀이 안전하게 흡수할 수 있는가”가 더 중요해집니다. PR이 논리적으로 나뉘는지, 테스트 결과를 신뢰할 수 있는지, secret이 노출되지 않는지, 외부 네트워크 접근이 통제되는지, 누가 어떤 환경을 바꿨는지 감사 로그가 남는지를 봐야 합니다.
또 하나 중요한 변화는 AI 도구가 개발자 개인의 생산성 도구를 넘어 팀의 운영 체계로 들어오고 있다는 점입니다. Cursor의 team context, Perplexity의 Teams와 enterprise connectors, Gemini의 Webhooks와 API 기반 agent workflow는 모두 개인 단축키가 아니라 조직 프로세스와 연결되는 기능입니다.
이 변화에서 얻을 수 있는 관찰 기준
이 이슈에서 얻을 수 있는 첫 번째 인사이트는 “AI 도구 선택은 단일 승자 고르기가 아니다”라는 점입니다. 풀스택 개발 워크플로는 여러 단계로 쪼개져 있고, 각 단계의 병목이 다릅니다.
두 번째 인사이트는 “에이전트의 성능보다 환경의 품질이 중요해진다”는 점입니다. 아무리 똑똑한 모델이라도 레포를 제대로 보지 못하고, dependencies를 설치하지 못하고, 테스트를 돌릴 수 없고, 필요한 secret에 안전하게 접근하지 못하면 실무에서는 제한적입니다. Cursor가 개발 환경, Dockerfile, build secrets, audit log를 강조하는 이유도 여기에 있습니다.
세 번째 인사이트는 “근거를 보여주는 AI”가 제품 기능의 기본값이 될 가능성입니다. Gemini API File Search의 page number, media_id, grounding metadata는 단순 답변 생성이 아니라, 사용자가 어떤 문서와 이미지 조각을 근거로 답이 나왔는지 확인할 수 있게 합니다. 이는 고객지원, 내부 지식검색, 법무·정책 문서 검색, 기술문서 검색에서 특히 중요합니다.
네 번째 인사이트는 “배포”의 의미가 나뉜다는 점입니다. Perplexity의 *.pplx.app publishing은 빠른 공유와 프로토타입 배포에는 유용하지만, 운영 서비스 배포와는 다릅니다. 앞으로 AI 도구는 “아이디어를 공유 가능한 앱으로 만드는 임시 배포”와 “보안·성능·규정 준수를 갖춘 프로덕션 배포” 사이의 경계를 더 자주 만들 것입니다.
다섯 번째 인사이트는 “비동기 AI 작업”이 일반 앱 아키텍처 안으로 들어온다는 점입니다. Webhooks는 긴 AI 작업이 끝났을 때 서버에 알림을 보내는 구조를 제공합니다. 이는 AI 기능이 단순 채팅창을 넘어, 백그라운드 job, 큐, 알림, 대시보드, 승인 워크플로와 연결되는 흐름을 보여줍니다.
결국 AI 개발 도구를 볼 때는 다음 질문을 던져야 합니다. 이 도구는 코드 작성 시간을 줄이는가, 리뷰 시간을 늘리는가? 개발 환경을 재현 가능하게 만드는가? 근거와 로그를 남기는가? 사람이 승인해야 할 지점을 명확히 해주는가? 우리 팀의 보안 정책 안에서 돌아갈 수 있는가?
결론
Cursor, Perplexity Computer, Gemini API의 최근 업데이트를 함께 보면 풀스택 개발자의 AI 워크플로가 어디로 가고 있는지 꽤 분명해집니다. 변화의 방향은 “코드 자동완성”에서 “작업 단위 자동화”로 이동하고 있습니다.
Cursor는 클라우드 에이전트가 실제 개발 환경에서 여러 레포를 다루고, Dockerfile 기반 설정과 build secrets, audit log, PR 리뷰 흐름 안에서 일하도록 만드는 쪽에 집중하고 있습니다. Perplexity Computer는 조사, 문서, 업무 워크플로, 웹 게시처럼 개발 전후의 산출물 제작을 넓히고 있습니다. Gemini API는 File Search, Webhooks, Deep Research Agent를 통해 개발자가 자기 제품 안에 RAG와 비동기 에이전트 기능을 붙일 수 있는 기반을 제공합니다.
그래서 풀스택 개발자에게 중요한 질문은 “AI 도구를 하나만 고른다면 무엇인가”가 아닙니다. 더 중요한 질문은 “기획/조사, 멀티레포 코드 수정, 테스트·리뷰, RAG·문서 검색, 배포·공유, 운영·보안 점검을 각각 어떤 도구와 어떤 승인 체계로 나눌 것인가”입니다.
AI 에이전트는 분명 더 많은 일을 맡게 될 것입니다. 하지만 그만큼 개발자의 역할도 사라지는 것이 아니라 바뀝니다. 직접 모든 코드를 쓰는 사람에서, 작업 범위를 정의하고, 결과를 검증하고, 시스템 권한과 보안 경계를 설계하는 사람으로 이동합니다.
이번 주제는 어떠셨나요? 개인적으로는 풀스택 개발자의 생산성 변화가 “더 빠른 코딩”보다 “더 잘 나눈 업무 흐름”에서 크게 나타날 것 같습니다. AI 도구를 도입할 때도 기능 목록만 보지 말고, 우리 팀의 병목이 어느 단계에 있는지 먼저 보는 것이 가장 현실적인 출발점인 것 같습니다. 긴 글 읽어주셔서 감사합니다.