핵심 요약
- Anthropic의 dreaming은 AI가 사람처럼 꿈을 꾸거나 의식을 갖는다는 뜻이 아니라, 에이전트가 남긴 세션 기록과 메모리 저장소를 검토해 다음 작업에 쓸 수 있는 형태로 정리하는 회고형 기능입니다.
- 이번 발표의 중요한 신호는 AI 에이전트 경쟁이 “좋은 프롬프트 한 번 쓰기”에서 “장기 업무 속에서 무엇을 기억하고, 무엇을 버리고, 어떻게 검증할지 설계하기”로 이동하고 있다는 점입니다.
- Claude Managed Agents의 업데이트는 dreaming, outcomes, multiagent orchestration, webhooks가 함께 묶여 있습니다. 이는 에이전트가 기억하고, 위임하고, 평가받고, 완료 상태를 외부 시스템에 알리는 구조로 발전하고 있음을 보여줍니다.
- 장기 업무 자동화에서 메모리는 성능 향상 가능성을 만들지만, 잘못된 선호 저장, 오래된 정보 유지, 컨텍스트 오염, 개인정보·보안 리스크도 함께 키울 수 있습니다.
- 앞으로 실무자가 봐야 할 역량은 Prompt Engineering만이 아니라 Context Engineering, 더 나아가 Agent Memory Engineering입니다.
목차
1. dreaming이라는 이름보다 중요한 질문
안녕하세요? 요즘 AI 에이전트 이야기를 따라가다 보면 “프롬프트를 어떻게 잘 쓰느냐”보다 더 복잡한 질문이 눈에 들어옵니다. 에이전트가 한 번의 대화가 아니라 며칠, 몇 주, 여러 세션에 걸쳐 일을 맡게 된다면, 무엇을 기억해야 하고 무엇을 잊어야 할까요?
Anthropic이 공개한 dreaming은 바로 이 질문을 건드립니다. 이름만 보면 AI가 사람처럼 꿈을 꾸는 기능처럼 들릴 수 있지만, 공식 자료 기준으로는 그런 의미가 아닙니다. 더 정확히 말하면 에이전트의 과거 세션과 메모리 저장소를 검토해 중복, 오래된 정보, 모순된 내용을 정리하고 다음 작업에 활용 가능한 메모리로 재구성하는 기능에 가깝습니다.
그래서 이 글의 핵심은 “AI가 꿈을 꾸기 시작했다”가 아닙니다. 오히려 반대입니다. 이제 AI 에이전트를 제대로 쓰려면 꿈이나 의식 같은 은유에 휩쓸리기보다, 작업 기록을 어떻게 정리하고 검증할지 설계해야 한다는 점이 중요해졌습니다.
2. Claude Managed Agents와 dreaming은 무엇인가
먼저 Claude Managed Agents부터 짚어보겠습니다. 공식 문서에서 Managed Agents는 Anthropic이 제공하는 관리형 에이전트 실행 환경입니다. 개발자가 직접 에이전트 루프, 도구 실행, 런타임을 모두 만들지 않아도, Claude가 파일을 읽고, 명령을 실행하고, 웹을 탐색하고, 코드를 실행할 수 있는 관리형 인프라를 제공하는 구조입니다.
이 환경은 특히 오래 걸리는 작업, 비동기 작업, 여러 도구 호출이 필요한 작업에 맞춰져 있습니다. 문서상 Managed Agents는 에이전트, 환경, 세션, 이벤트라는 네 가지 개념을 중심으로 구성되며, 세션 기록은 서버 측에 유지되고 전체 이벤트 히스토리를 가져올 수 있습니다.
dreaming은 이 구조 위에 얹힌 메모리 정리 기능입니다. 에이전트가 작업하면서 memory store에 내용을 저장하면, 시간이 지나며 중복된 항목, 서로 충돌하는 선호, 더 이상 맞지 않는 프로젝트 정보가 쌓일 수 있습니다. Anthropic의 문서는 이를 정리하기 위해 dream이 기존 메모리 스토어와 과거 세션 transcript를 읽고, 새롭게 재구성된 메모리 스토어를 만든다고 설명합니다.
중요한 점은 입력 메모리 스토어를 바로 덮어쓰지 않는다는 것입니다. 공식 문서 기준 dream의 입력 스토어는 수정되지 않고, 결과로 별도의 출력 메모리 스토어가 생성됩니다. 개발자는 그 결과를 검토한 뒤 향후 세션에 붙이거나 폐기할 수 있습니다.
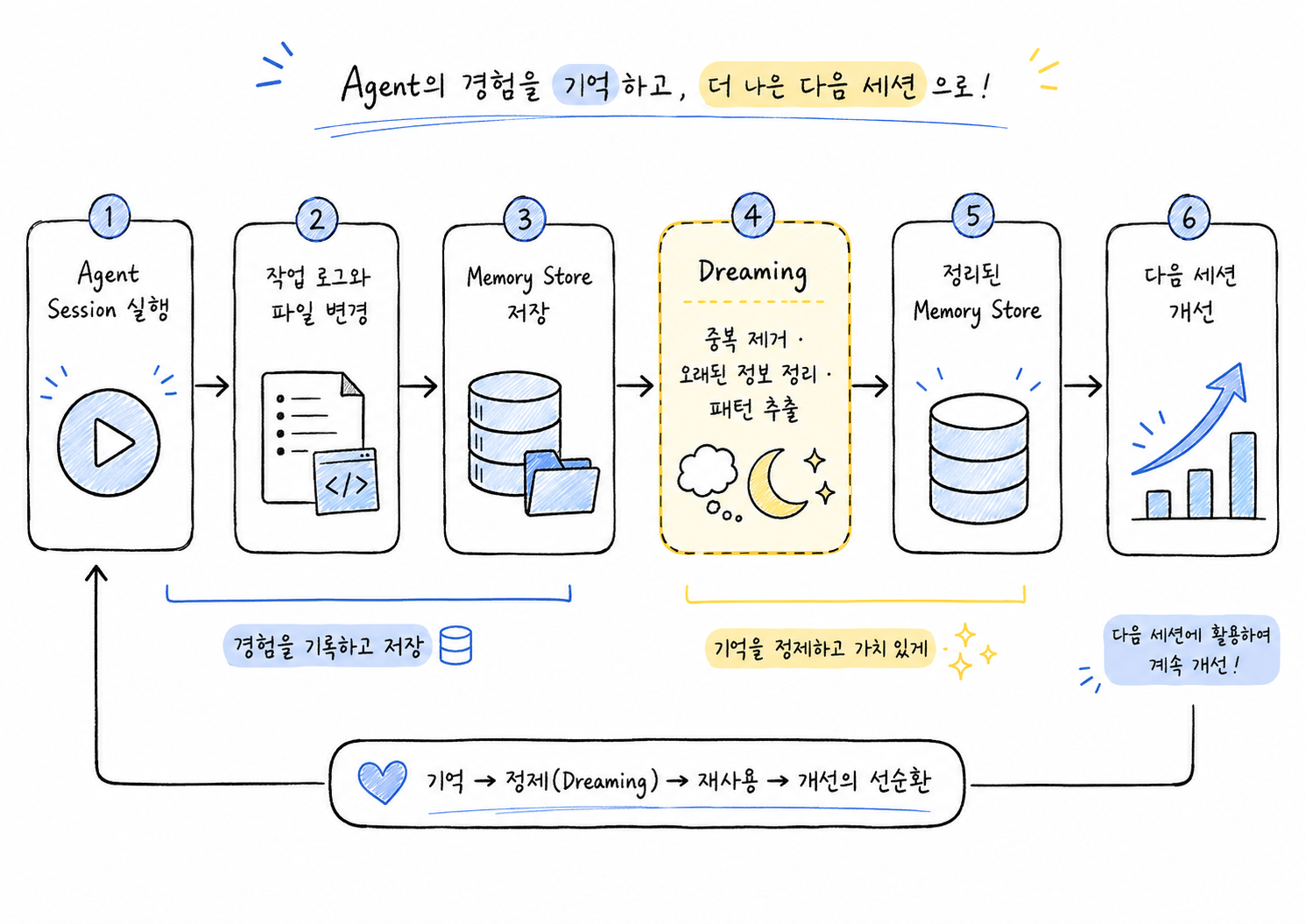
에이전트 실행 기록이 메모리 스토어로 저장되고 dreaming 과정을 거쳐 다음 세션에 활용되는 흐름도
3. Anthropic은 무엇을 발표했나
Anthropic은 2026년 5월 6일 공식 블로그에서 New in Claude Managed Agents: dreaming, outcomes, and multiagent orchestration이라는 제목의 발표를 냈습니다. 이 발표에서 dreaming은 Claude Managed Agents의 research preview로 소개됐고, outcomes, multiagent orchestration, webhooks도 Managed Agents 개발자를 위한 업데이트로 함께 공개됐습니다.
공식 발표 기준으로 구분하면 이렇습니다. dreaming은 research preview입니다. 반면 같은 발표의 시작 안내에서는 outcomes, multiagent orchestration, memory가 Managed Agents의 public beta로 제공된다고 설명합니다. 다만 개발 문서에서는 Managed Agents 전체 API 요청에 managed-agents-2026-04-01 beta header가 필요하다고 되어 있으므로, 실제 도입 단계에서는 베타 성격의 플랫폼 기능으로 보는 편이 안전합니다.
Reuters는 같은 날 Anthropic이 샌프란시스코 개발자 행사에서 dreaming을 공개했다고 보도했습니다. Reuters 보도 기준 이 기능은 세션 사이에 과거 작업을 검토하고, 패턴을 찾고, 사용자 선호와 기타 컨텍스트 파일을 업데이트하는 방향으로 소개됐습니다.
여기서 흥미로운 점은 발표가 단일 기능 소개가 아니라는 것입니다. dreaming은 메모리 정리, outcomes는 성과 기준 평가, multiagent orchestration은 하위 에이전트 위임, webhooks는 장기 실행 상태 알림과 연결됩니다. 즉 에이전트가 “한 번 답하는 챗봇”에서 “작업을 맡고, 기억하고, 평가받고, 후속 시스템과 연결되는 실행 단위”로 이동하고 있다는 신호로 볼 수 있습니다.
4. 왜 프롬프트보다 메모리 설계가 중요해지는가
지금까지 많은 AI 활용법은 Prompt Engineering에 집중돼 있었습니다. 어떤 역할을 부여할지, 어떤 출력 형식을 요구할지, 어떤 예시를 줄지 고민하는 방식입니다. 짧은 대화나 단발성 작업에서는 여전히 중요합니다.
하지만 에이전트가 장기 업무를 맡으면 문제가 달라집니다. 매번 같은 설명을 다시 입력하지 않으려면, 에이전트는 프로젝트 규칙, 사용자 선호, 과거 실수, 검증 기준, 반복되는 업무 패턴을 어딘가에 저장해야 합니다. 공식 메모리 문서도 Managed Agents의 각 세션은 기본적으로 새 컨텍스트에서 시작하며, memory store가 사용자 선호, 프로젝트 관례, 과거 실수, 도메인 컨텍스트를 세션 간에 이어주는 역할을 한다고 설명합니다.
여기서 생기는 새로운 역량을 이 글에서는 Agent Memory Engineering이라고 부르겠습니다. 공식 제품명이 아니라, 현재 흐름을 설명하기 위한 분석 용어입니다. 핵심은 에이전트가 “무엇을 기억할지”뿐 아니라 “무엇을 기억하지 말아야 하는지”, “언제 오래된 정보를 폐기해야 하는지”, “기억된 내용이 사실인지 어떻게 검증해야 하는지”까지 설계하는 일입니다.
좋은 프롬프트 한 번이 아니라, 좋은 업무 기억 시스템이 경쟁력이 되는 셈입니다. 특히 업무 자동화, 개발자 도구, 리서치 에이전트, 문서 처리 에이전트처럼 반복성과 누적성이 큰 영역에서는 이 차이가 더 커집니다.
5. 에이전트 메모리는 어떻게 작동하는가
Anthropic 문서 기준 memory store는 Claude에 최적화된 텍스트 문서 컬렉션입니다. 세션에 붙이면 컨테이너 안의 디렉터리처럼 마운트되고, 에이전트는 일반 파일 도구로 그 내용을 읽고 씁니다. 각 메모리는 경로로 식별되며 API나 Console에서 직접 읽고 편집할 수 있습니다.
메모리에는 버전 관리와 감사 추적도 들어갑니다. 공식 문서는 메모리 변경마다 불변 버전이 생성되고, 누가 무엇을 언제 바꿨는지 감사하거나 이전 스냅샷을 검토하고 민감한 내용을 삭제 요청에 맞춰 redaction할 수 있다고 설명합니다.
dreaming은 이 메모리 계층을 정리하는 회고형 파이프라인입니다. 문서 기준 dream은 기존 메모리 스토어와 선택적으로 최대 100개 세션을 입력으로 받아 중복을 병합하고, 오래되었거나 모순된 항목을 최신 값으로 교체하며, 새 인사이트를 표면화합니다. research preview 기간의 지원 모델은 claude-opus-4-7, claude-sonnet-4-6으로 명시돼 있습니다.
여기에 outcomes가 붙으면 에이전트는 “무엇이 좋은 결과인지”를 기준표로 평가받을 수 있습니다. 공식 문서 기준 outcome은 세션을 단순 대화에서 작업으로 끌어올리는 개념이며, 별도의 grader가 별도 컨텍스트 창에서 산출물을 rubric에 따라 평가합니다. 부족한 부분이 있으면 그 피드백이 에이전트에게 전달돼 다음 반복으로 이어집니다.
multiagent orchestration은 리드 에이전트가 복잡한 일을 나누고 전문 하위 에이전트에 위임하는 구조입니다. 공식 발표는 리드 에이전트가 작업을 쪼개고, 각 전문 에이전트가 자체 모델, 프롬프트, 도구를 가지고 병렬로 작업하며, Console에서 어느 에이전트가 무엇을 어떤 순서로 했는지 추적할 수 있다고 설명합니다.
따라서 핵심은 “에이전트 수가 많아졌다”가 아닙니다. 역할이 분리되고, 작업 경로가 추적 가능해지고, 결과가 기준표로 평가되며, 그 과정에서 유의미한 학습만 메모리에 남는 구조가 중요해지는 것입니다.
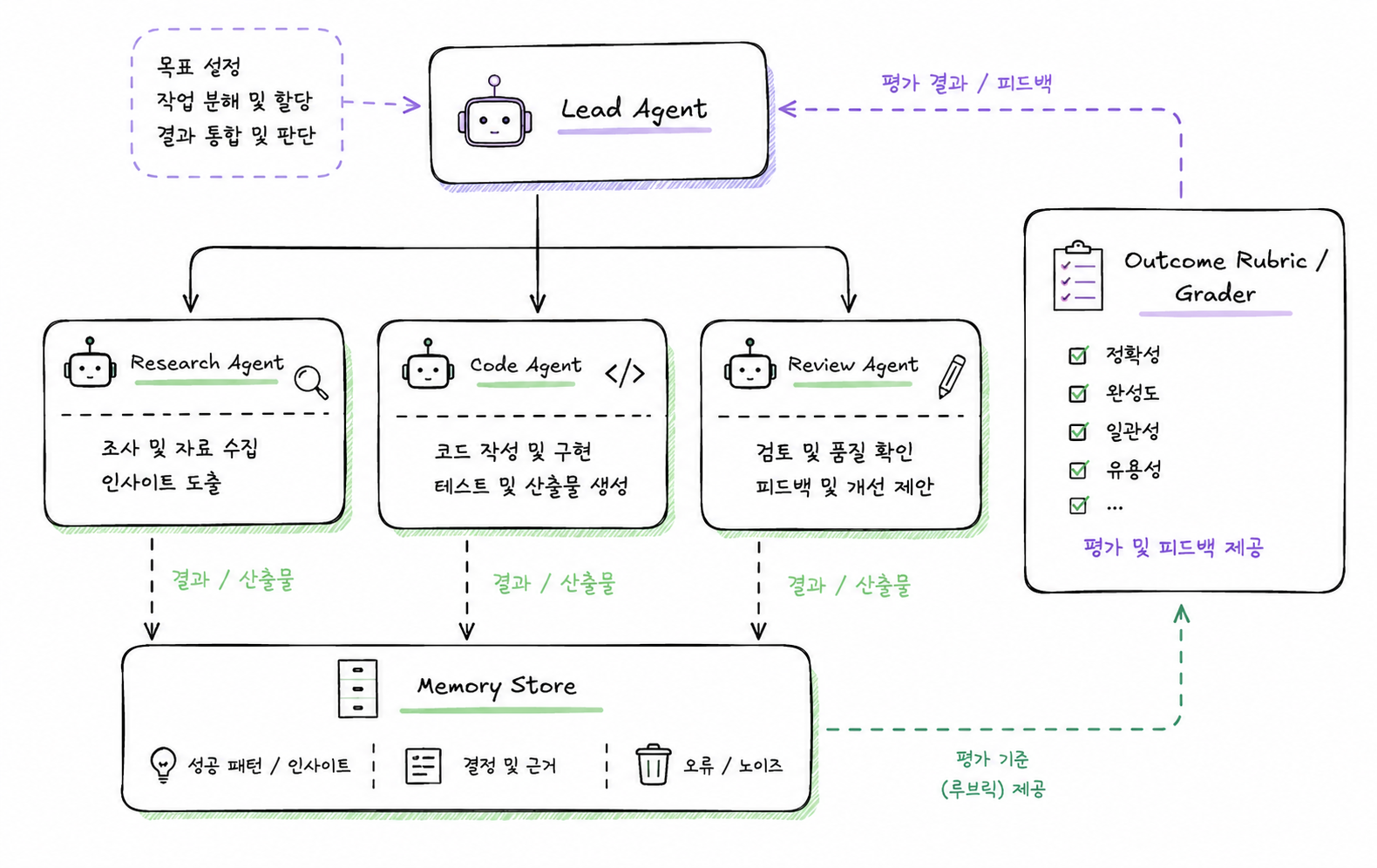
리드 에이전트가 하위 에이전트에 작업을 나누고 결과를 기준표로 검증하는 구조
6. Prompt, Context, Agent Memory Engineering 비교
이 흐름을 이해하려면 세 가지 개념을 구분하는 편이 좋습니다. Prompt Engineering, Context Engineering, Agent Memory Engineering입니다. 셋은 서로 대체 관계가 아니라 단계적으로 확장되는 관계에 가깝습니다.
| 구분 | 쉽게 말하면 | 주로 다루는 것 | 잘못 설계했을 때 문제 | 장기 업무에서의 역할 |
|---|---|---|---|---|
| Prompt Engineering | 이번 작업을 어떻게 지시할 것인가 | 역할, 목표, 출력 형식, 제약 조건 | 모호한 답변, 형식 오류, 작업 범위 오해 | 단발성 작업의 품질을 좌우 |
| Context Engineering | 이번 작업에 어떤 자료를 넣을 것인가 | 문서, 코드, 검색 결과, 사용자 입력, 도구 결과 | 불필요한 자료 과다, 핵심 정보 누락, 컨텍스트 오염 | 작업별 정확도와 근거 품질을 좌우 |
| Agent Memory Engineering | 반복 업무에서 무엇을 남기고 버릴 것인가 | 사용자 선호, 프로젝트 규칙, 과거 실수, 검증 기준, 업데이트 이력 | 잘못된 선호 저장, 오래된 정보 유지, 보안 위험, 반복 오류 | 장기 업무 자동화의 지속 품질을 좌우 |
Prompt Engineering은 “이번에 무엇을 시킬까”에 가깝습니다. Context Engineering은 “이번 작업에 필요한 자료를 어떻게 구성할까”에 가깝습니다. 반면 Agent Memory Engineering은 “이 에이전트가 앞으로도 반복해서 참고할 지식을 어떻게 관리할까”에 가깝습니다.
이 차이는 생각보다 큽니다. 프롬프트는 실행 전 지시문이고, 컨텍스트는 실행 중 참고 자료입니다. 메모리는 실행 이후 남기는 지식입니다. 장기 업무 자동화에서는 실행 이후 남긴 지식이 다음 실행의 품질을 바꾸기 때문에, 메모리 설계가 곧 에이전트 운영 설계가 됩니다.
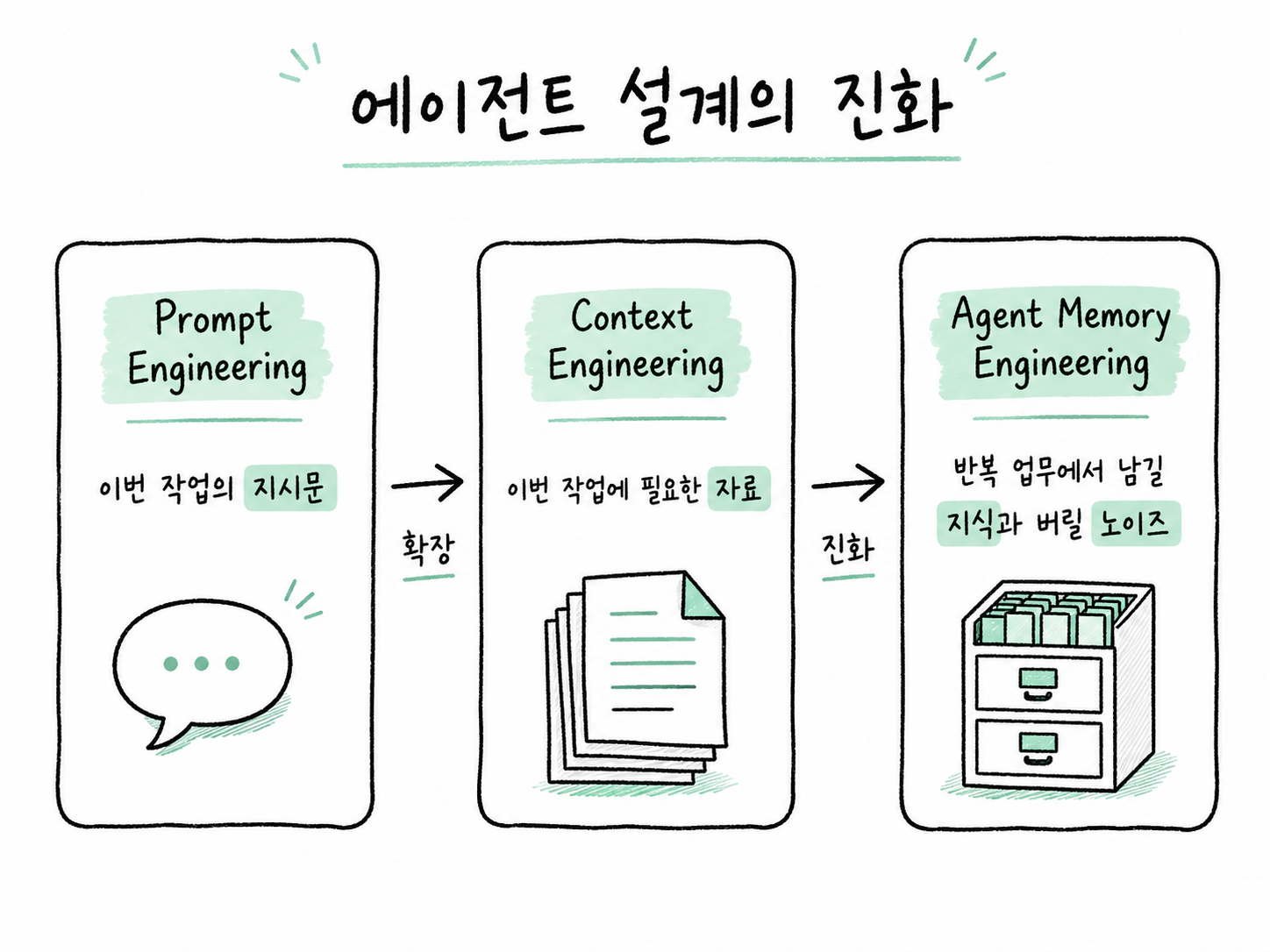
Prompt Engineering, Context Engineering, Agent Memory Engineering의 차이를 비교하는 개념도
7. 아직 확인해야 할 한계와 리스크
먼저 성능 개선 폭은 조심해서 봐야 합니다. 공식 블로그에는 고객사 사례로 Harvey가 dreaming을 사용해 테스트에서 완료율이 약 6배 올랐다는 내용이 나오지만, 이것은 특정 고객·특정 테스트 환경의 사례입니다. 일반적인 모든 에이전트 작업에서 dreaming 자체가 어느 정도 성능 개선을 보장하는지는 공개 자료 기준으로 단정하기 어렵습니다.
사용 가능 대상도 주의가 필요합니다. 공식 발표 기준 dreaming은 Managed Agents에서 request access가 필요한 research preview입니다. 공식 문서 기준 Claude Managed Agents 자체는 beta header를 요구하며 API 계정에서 기본 활성화된다고 설명되지만, 일부 기능은 별도 접근 요청이나 베타 조건이 붙을 수 있습니다.
지원 모델과 한도는 문서 기준으로는 비교적 분명합니다. dreaming은 research preview 기간에 claude-opus-4-7, claude-sonnet-4-6을 지원하고, 한 번의 dream에 최대 100개 세션, instructions 4,096자 제한이 있습니다. 비용은 선택한 모델의 표준 API 토큰 요율로 청구되며, 입력 세션 수와 길이에 따라 대체로 선형적으로 증가한다고 문서가 설명합니다.
메모리 저장 한도는 더 세밀하게 봐야 합니다. memory store 문서 기준 개별 메모리는 100kB, 약 25k tokens로 제한되며, 한 세션에는 최대 8개의 메모리 스토어를 붙일 수 있습니다. 다만 기본 capacity와 rate limit은 베타 기간에 적용되고, 더 높은 한도는 지원팀에 문의하라는 형태로 안내돼 있어 실제 워크로드별 한도는 추가 확인이 필요합니다.
가장 중요한 리스크는 컨텍스트 오염입니다. 공식 문서도 read_write 메모리 스토어가 기본값이며, 에이전트가 사용자 입력, 웹 콘텐츠, 외부 도구 결과처럼 신뢰할 수 없는 입력을 처리할 때 프롬프트 인젝션이 성공하면 악성 내용이 메모리에 기록될 수 있다고 경고합니다. 이후 세션이 그 내용을 신뢰된 메모리처럼 읽게 될 수 있기 때문에, 참조용 자료나 공유 지식은 read_only로 관리하는 설계가 필요합니다.
지원 국가도 dreaming 전용 목록은 별도로 확인되지 않습니다. Anthropic의 지원 국가 페이지는 상업용 API access 대상 국가와 지역을 나열하며 South Korea도 포함하지만, 특정 research preview 기능의 지역별 제공 여부는 별도 접근 승인과 계정 조건에 따라 달라질 수 있으므로 도입 전 확인이 필요합니다.
마지막으로 이름의 문제도 있습니다. WIRED는 dreaming 같은 이름이 AI 기능을 인간의 인지 과정처럼 느끼게 만들 수 있다고 비판했습니다. 이 지적은 단순한 말꼬리 잡기가 아닙니다. 장기 업무 자동화에서 사용자가 에이전트를 과신하면, 메모리에 저장된 오류나 오래된 선호가 더 위험해질 수 있기 때문입니다.
8. 실무자에게 주는 의미
IT 실무자와 개발자가 이번 이슈에서 봐야 할 것은 기능명보다 구조입니다. dreaming은 에이전트가 실행을 마친 뒤 무엇을 남길지 정리하는 계층입니다. outcomes는 산출물이 기준을 충족했는지 평가하는 계층입니다. multiagent orchestration은 일을 나누고 모으는 계층입니다. webhooks는 장기 실행 상태를 외부 시스템으로 전달하는 계층입니다. 공식 webhook 문서는 장기 실행 세션에서 주요 상태 변경을 polling 없이 알림으로 받을 수 있다고 설명합니다.
이 네 가지가 함께 가리키는 방향은 분명합니다. 에이전트 플랫폼의 경쟁은 더 이상 “모델이 똑똑한가”만으로 설명되지 않습니다. 모델을 둘러싼 실행 환경, 메모리 구조, 평가 루프, 위임 구조, 관찰 가능성이 함께 경쟁력이 됩니다.
실무자 관점에서는 에이전트 도입 질문도 바뀌어야 합니다. “이 프롬프트를 잘 쓰면 되나?”에서 “이 에이전트가 반복 업무를 하며 어떤 기억을 축적하나?”, “그 기억은 누가 검토하나?”, “오류가 저장되면 어떻게 되돌리나?”, “민감 정보가 메모리에 남으면 어떻게 지우나?”, “성과 기준은 누가 정의하나?”로 이동해야 합니다.
특히 개발자 도구와 업무 자동화에서는 이 변화가 더 빠르게 드러날 가능성이 큽니다. 코드베이스 규칙, 테스트 습관, 배포 절차, 팀의 리뷰 기준은 한 번의 프롬프트보다 장기 기억에 더 적합한 지식입니다. 반대로 일회성 디버깅 힌트, 잘못된 임시 우회책, 오래된 API 사양은 메모리에 남기면 다음 작업을 망칠 수 있는 노이즈입니다.
9. 이 글에서 얻을 수 있는 인사이트
첫 번째 인사이트는 “메모리는 많을수록 좋은 것이 아니다”입니다. 좋은 메모리는 많은 정보가 아니라, 다음 작업에 재사용할 가치가 있는 정보입니다. 에이전트가 모든 대화와 모든 로그를 기억하게 만드는 방식은 오히려 컨텍스트 오염을 키울 수 있습니다.
두 번째 인사이트는 “회고는 자동화될 수 있지만, 기준은 사람이 설계해야 한다”입니다. dreaming이 중복을 정리하고 패턴을 찾을 수는 있어도, 무엇이 진짜 중요한 업무 지식인지, 무엇이 민감 정보인지, 무엇을 팀 표준으로 삼을지는 제품과 조직의 판단이 필요합니다.
세 번째 인사이트는 “에이전트 운영은 작은 지식관리 시스템이 된다”입니다. 과거에는 노션 문서, 위키, 코드 컨벤션, 리뷰 체크리스트가 사람이 보는 지식관리 시스템이었다면, 이제는 에이전트도 그런 지식을 읽고 쓰는 주체가 됩니다. 따라서 문서화와 메모리 설계가 점점 더 가까워집니다.
네 번째 인사이트는 “검증 없는 메모리는 위험하다”입니다. 장기 업무 자동화에서 잘못 저장된 선호는 반복 오류가 되고, 오래된 정보는 잘못된 판단의 근거가 되며, 공격자가 심어둔 문구는 다음 세션의 지시처럼 작동할 수 있습니다. 메모리에는 생성보다 검토, 접근권한, 감사 추적, 삭제 정책이 더 중요해질 수 있습니다.
10. 결론
Anthropic의 dreaming은 AI가 사람처럼 꿈을 꾸는 기능이 아닙니다. 공개 자료 기준으로 보면, 이는 에이전트의 작업 기록과 메모리 저장소를 검토해 다음 세션에서 쓸 수 있는 고신호 메모리로 정리하는 회고형 기능입니다. 이름은 흥미롭지만, 실제 의미는 훨씬 실무적입니다.
이번 발표가 보여준 흐름은 분명합니다. AI 에이전트 경쟁은 단순 프롬프트 작성과 도구 호출을 넘어, 세션 기록, 메모리 정리, 작업 회고, 하위 에이전트 위임, 성과 기준 평가로 확장되고 있습니다. 좋은 프롬프트를 한 번 쓰는 능력보다, 에이전트가 장기 업무 속에서 무엇을 기억하고 무엇을 버리고 어떻게 검증할지 설계하는 능력이 더 중요해지고 있습니다.
그래서 다음 키워드는 Agent Memory Engineering입니다. 이것은 화려한 마케팅 용어가 아니라, 장기 업무 자동화를 실제 업무에 넣으려는 팀이 반드시 마주하게 될 운영 문제입니다. 앞으로 AI 에이전트를 볼 때는 “얼마나 똑똑한가”만 보지 말고, “어떻게 기억하고, 어떻게 잊고, 어떻게 검증하는가”를 함께 봐야 합니다.