Meta의 Muse Spark 발표는 “가장 큰 AI 모델이 이긴다”는 이야기보다, “같은 성능을 더 적은 비용과 더 빠른 속도로 제공할 수 있느냐”가 중요해지고 있다는 신호에 가깝습니다.
AI 모델 경쟁은 여전히 성능을 겨루고 있지만, 이제는 파라미터 수나 벤치마크 점수만으로 설명하기 어려워졌습니다. 모델을 학습시키는 비용, 답변할 때 드는 연산 비용, 응답 속도, 실제 서비스에 얼마나 빨리 넣을 수 있는지가 함께 중요해지고 있습니다.
Muse Spark를 “Meta가 최고 성능 모델을 냈다”는 식으로 읽으면 핵심을 놓치기 쉽습니다. 더 정확한 관점은 Meta가 AI 모델 경쟁을 효율성, 추론 구조, 제품 통합 중심으로 다시 정리하려 한다는 것입니다.
앞으로 AI 모델 발표를 볼 때 중요한 질문은 “몇 점을 냈나?”뿐만이 아닙니다. “그 성능을 어떤 비용으로, 어떤 속도로, 어떤 제품 경험 안에서 제공할 수 있는가?”가 더 실무적인 질문이 됩니다.
목차
먼저 답부터: AI 모델 경쟁은 크기보다 효율을 함께 보기 시작했습니다
AI 모델 경쟁의 다음 기준은 단순한 파라미터 수가 아닙니다. 더 큰 모델을 만드는 경쟁은 계속되겠지만, 이제는 “얼마나 큰가?”만큼 “얼마나 효율적으로 작동하는가?”가 중요해지고 있습니다.
여기서 효율이란 단순히 서버 비용을 줄인다는 뜻만은 아닙니다. 모델을 학습시키는 데 드는 연산량, 사용자가 질문할 때마다 드는 추론 비용, 답변이 나오기까지 걸리는 시간, 실제 앱과 서비스에 적용되는 속도까지 포함합니다.
Meta의 Muse Spark 발표가 흥미로운 이유도 여기에 있습니다. Meta는 Muse Spark를 네이티브 멀티모달 reasoning 모델로 설명하면서, tool-use, visual chain of thought, multi-agent orchestration 같은 기능을 강조했습니다. 다만 이 표현들을 어렵게 받아들일 필요는 없습니다. 쉽게 말하면, 텍스트와 이미지를 함께 이해하고, 도구를 사용하며, 여러 방식으로 문제를 나누어 풀 수 있는 모델을 지향한다는 뜻입니다.
이 글의 핵심은 간단합니다. 앞으로 AI 모델 발표를 볼 때는 “가장 똑똑한 모델인가?”뿐 아니라 “그 똑똑함을 감당 가능한 비용과 속도로 실제 서비스에 넣을 수 있는가?”를 함께 봐야 합니다.
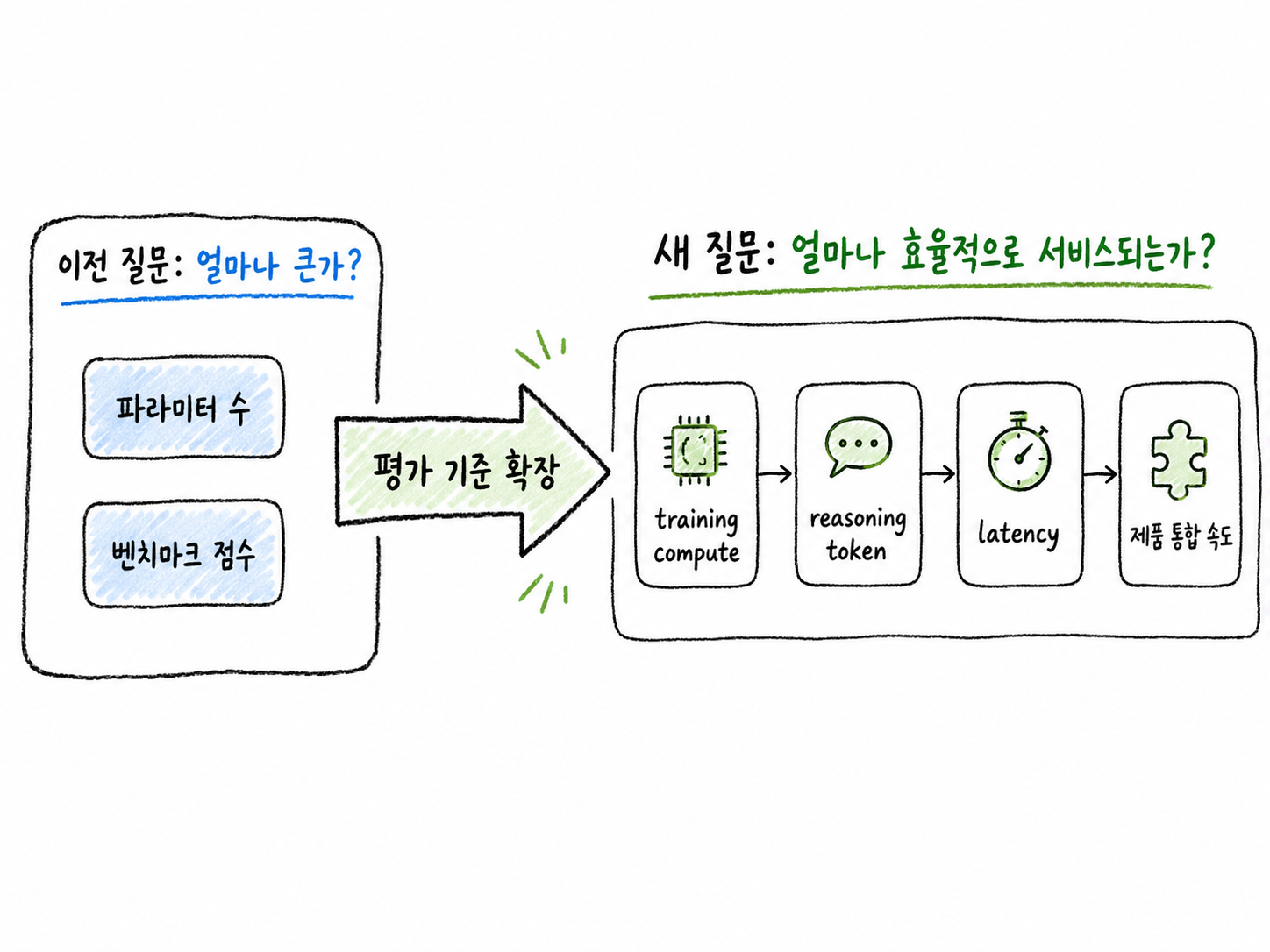
AI 모델 경쟁의 평가 기준이 파라미터 수에서 compute 효율성, reasoning token, latency, 제품 통합 속도로 확장되는 흐름을 보여주는 비교 다이어그램
사실 확인: Muse Spark는 최고 모델 선언보다 효율 전략으로 보는 편이 안전합니다
먼저 확인해야 할 점은 Muse Spark를 “업계 최고 성능 모델”로 단정하면 안 된다는 것입니다. 공개 자료 기준 Muse Spark는 Meta가 2026년 4월 8일 발표한 Muse 계열 첫 모델입니다. 중요한 포인트는 최고 성능 선언보다, Meta가 모델 경쟁의 기준을 효율과 제품 적용 쪽으로 넓혀 설명했다는 데 있습니다.
제공 범위도 구분해서 봐야 합니다. 발표 시점 기준 Muse Spark는 Meta AI 앱과 meta.ai에서 제공되는 것으로 설명됐고, 일부 사용자 또는 일부 파트너 대상 private API preview도 언급됐습니다. 반면 Facebook, Instagram, WhatsApp, Messenger, AI glasses 같은 서비스 확장은 “이미 모든 곳에 적용됐다”기보다 향후 확장 또는 점진적 롤아웃으로 보는 편이 안전합니다.
Meta가 강조한 핵심 주장은 Llama 4 Maverick 대비 같은 수준의 capability에 도달하는 데 필요한 학습 연산량을 크게 줄였다는 것입니다. 다만 이 내용은 Meta의 자체 평가와 설명을 바탕으로 한 주장입니다. 따라서 “효율이 개선됐다고 Meta가 설명했다”는 수준으로 받아들이고, 외부 평가와 함께 보는 것이 좋습니다.
안전성 측면에서도 단정은 피해야 합니다. Meta는 Muse Spark Safety & Preparedness Report에서 배포 맥락의 잔여 위험을 수용 가능한 수준으로 평가했지만, 동시에 jailbreak, prompt injection, agentic misuse 같은 영역은 계속 개선해야 할 부분으로 제시했습니다. 즉, 성능과 효율만큼 안전성 평가도 함께 봐야 합니다.
핵심 내용 설명: 왜 연산 비용과 응답 속도가 중요해졌을까
그동안 AI 모델 발표를 볼 때 가장 눈에 잘 들어오는 기준은 파라미터 수와 벤치마크 점수였습니다. 모델이 몇 B인지, 어떤 시험에서 몇 점을 냈는지, 기존 모델보다 얼마나 좋아졌는지가 주된 관심사였습니다.
하지만 실제 서비스에서는 이 기준만으로 충분하지 않습니다. 아무리 성능이 좋아도 응답이 느리거나, 한 번 답변할 때마다 비용이 너무 많이 들거나, 제품 안에 안정적으로 넣기 어렵다면 대규모 서비스로 확장하기 어렵습니다.
Muse Spark 발표에서 중요한 키워드는 학습 비용과 사용 시점의 비용입니다. 학습 비용은 모델을 만드는 데 드는 비용이고, 사용 시점의 비용은 사용자가 질문할 때마다 발생하는 비용입니다. 기업 입장에서는 둘 다 중요하지만, 실제 서비스를 운영할 때는 사용자가 늘어날수록 매번 발생하는 추론 비용과 응답 속도가 더 민감한 문제가 됩니다.
특히 reasoning 모델에서는 “얼마나 오래 생각하느냐”가 비용과 속도에 직접 영향을 줍니다. 모델이 어려운 문제를 풀기 위해 더 많은 단계를 거치면 답변 품질은 좋아질 수 있지만, 그만큼 토큰 사용량이 늘고 응답도 느려질 수 있습니다.
그래서 reasoning token이라는 개념이 중요해집니다. 쉽게 말하면, 모델이 답을 내기 위해 내부적으로 쓰는 생각의 양에 가깝습니다. 같은 품질의 답을 더 적은 reasoning token으로 만들 수 있다면, 사용자는 더 빠르게 답을 받고 기업은 비용을 줄일 수 있습니다.
Meta가 multi-agent orchestration을 강조한 것도 같은 흐름입니다. 하나의 모델이 오래 고민하는 대신, 여러 흐름으로 문제를 나누어 풀고 결과를 모으면 어려운 문제를 더 효율적으로 처리할 수 있습니다. 이것은 단순히 모델 자체가 똑똑한지를 넘어, 모델을 어떤 실행 구조 안에서 돌리느냐가 중요해졌다는 뜻입니다.
결국 Muse Spark의 의미는 모델 하나의 성능표에만 있지 않습니다. Meta가 AI 모델을 실제 제품 안에서 빠르고 넓게 쓰기 위해, 비용과 속도, 추론 구조를 함께 최적화하려 한다는 점에 있습니다.
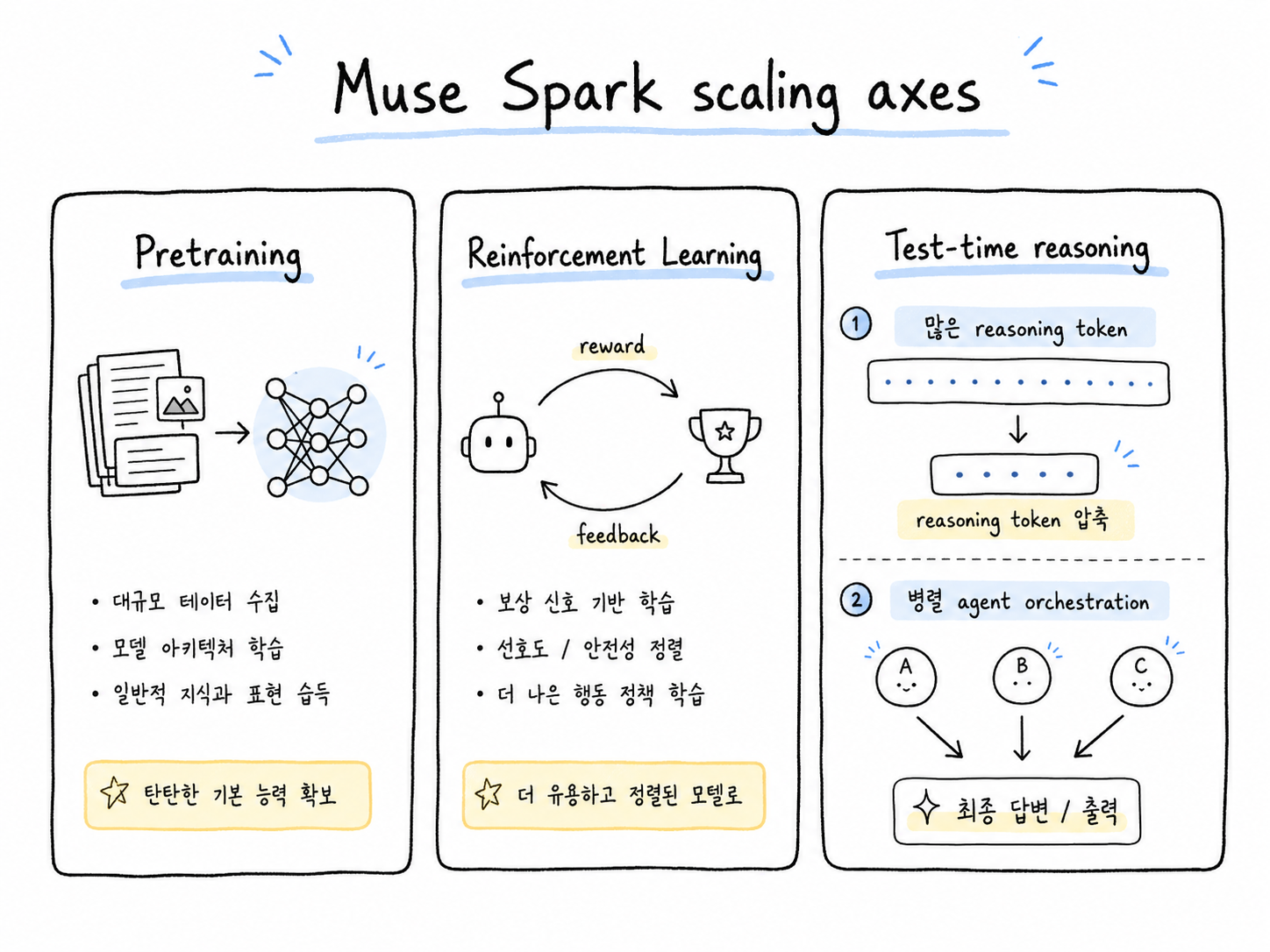
Muse Spark의 pretraining, reinforcement learning, test-time reasoning 축과 reasoning token 압축, 병렬 에이전트 흐름을 설명한 다이어그램
비교 또는 구조화: 모델 발표를 볼 때 질문이 달라졌습니다
Muse Spark 이후 모델 발표를 읽는 방식은 조금 달라질 필요가 있습니다. 예전에는 “얼마나 큰 모델인가?”, “벤치마크 점수가 몇 점인가?”가 먼저 보였다면, 이제는 “이 모델을 실제 서비스에서 얼마나 효율적으로 쓸 수 있는가?”를 함께 봐야 합니다.
| 비교 기준 | 예전 질문 | 이제 더 중요한 질문 |
|---|---|---|
| 모델 크기 | 몇 B 모델인가? | 그 크기가 실제 서비스 비용과 속도에 어떤 영향을 주는가? |
| 학습 효율 | 얼마나 큰 자원으로 학습했는가? | 비슷한 성능에 도달하는 데 필요한 연산량을 줄였는가? |
| 추론 비용 | 어려운 문제를 잘 푸는가? | 답을 내기 위해 얼마나 많은 토큰과 시간이 필요한가? |
| 응답 속도 | 정답률이 높은가? | 사용자가 기다릴 수 있는 시간 안에 답하는가? |
| 제품 통합 | 모델 API가 공개됐는가? | 실제 앱과 웹 서비스 안에 얼마나 빠르게 들어가는가? |
| 안전성 | 성능표가 있는가? | 평가 방법과 안전성 문서가 함께 공개됐는가? |
이 변화는 AI 산업을 따라가는 독자에게도 중요합니다. 이제 모델 발표를 볼 때는 “새 모델이 나왔다”에서 멈추지 말고, 그 모델이 실제 사용자 경험과 기업 비용 구조를 어떻게 바꾸는지까지 봐야 합니다.
실무적 의미: 좋은 모델보다 운영 가능한 모델이 중요합니다
IT 기획자와 개발자에게 Muse Spark 발표가 주는 가장 큰 메시지는 모델 선택 기준의 변화입니다. 앞으로 AI 서비스를 만들 때는 “가장 높은 성능 모델을 붙이면 된다”가 아니라 “우리 서비스에서 감당 가능한 비용과 속도로 운영할 수 있는가?”를 먼저 생각해야 합니다.
예를 들어 고객지원 챗봇처럼 요청이 많은 서비스에서는 모든 질문에 가장 무거운 reasoning 모드를 쓰기 어렵습니다. 간단한 문의는 빠른 방식으로 처리하고, 복잡한 문제에만 더 깊게 생각하는 모드나 여러 에이전트를 조합하는 방식을 쓰는 편이 현실적입니다.
개발자 관점에서는 모델 호출 방식 자체가 아키텍처 설계 요소가 됩니다. 모델을 한 번만 호출할지, 외부 도구를 붙일지, 여러 하위 에이전트를 병렬로 실행할지, 캐시를 적용할 수 있을지에 따라 비용과 응답 속도가 달라집니다.
Meta의 전략은 특히 소비자 제품을 가진 기업에 시사점이 큽니다. Muse Spark는 독립적인 모델 API 상품이라기보다 Meta AI 앱, meta.ai, 그리고 향후 여러 Meta 서비스 안에 들어갈 AI 경험의 기반으로 설명됩니다. 즉, 모델 경쟁은 점점 “누가 더 똑똑한 모델을 만들었나”에서 “누가 더 많은 사용자 접점에 AI를 자연스럽게 배포할 수 있나”로 확장되고 있습니다.
물론 이 흐름에는 주의할 점도 있습니다. 개인화 AI가 강해질수록 사용자의 관심사, 행동 데이터, 콘텐츠 맥락을 어떻게 활용하는지가 중요해집니다. 따라서 기업이 AI 모델을 도입할 때는 성능표만 비교하지 말고, 비용 구조, 응답 속도, 데이터 처리 정책, 안전성 문서, 실제 제품 적용 범위를 함께 봐야 합니다.
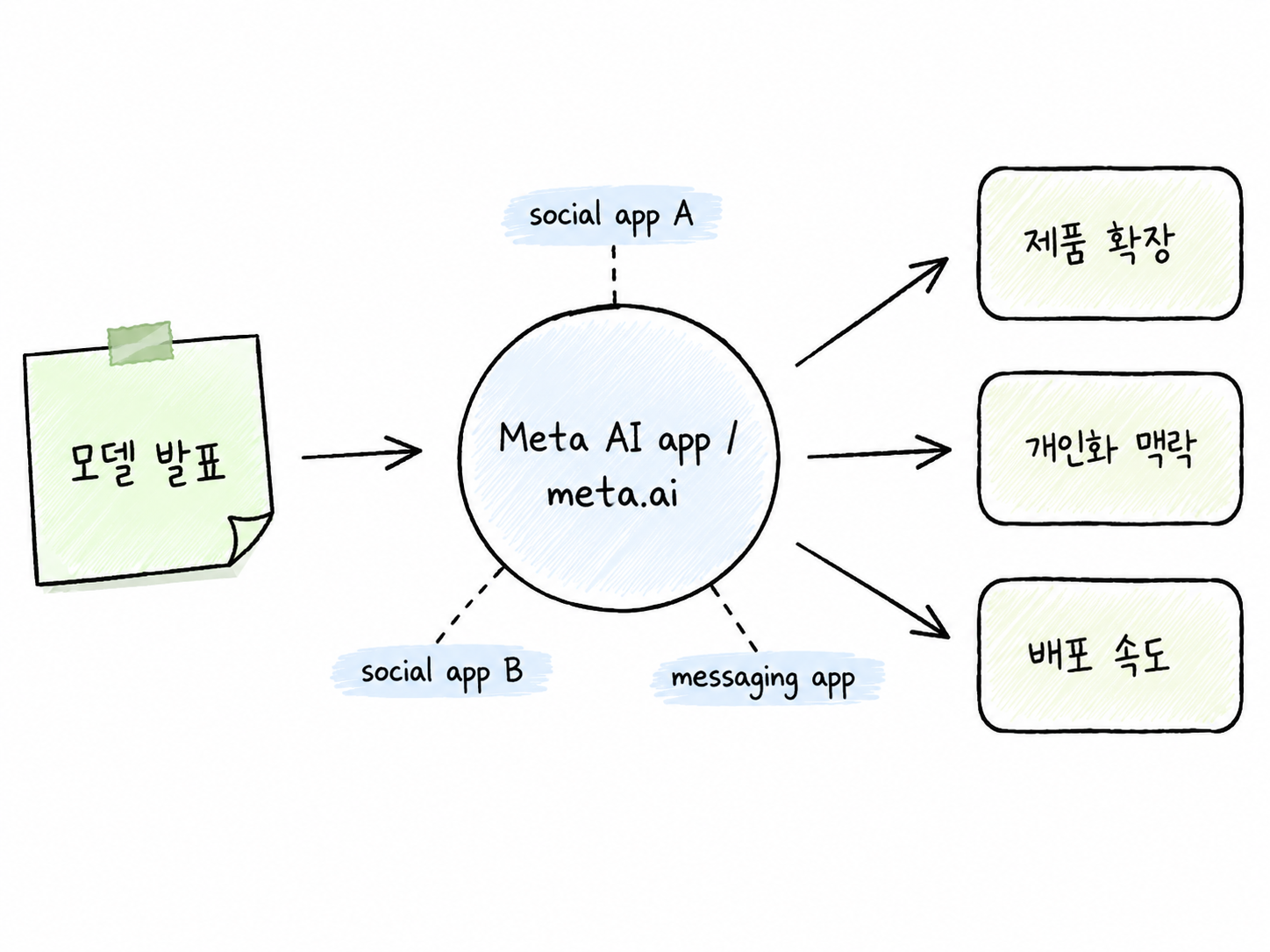
Muse Spark가 Meta AI 앱과 meta.ai에서 시작해 여러 서비스로 확장되는 제품 통합 흐름을 보여주는 다이어그램
결론: 다음 경쟁력은 효율적으로 생각하고 빠르게 제품에 들어가는 능력입니다
Muse Spark 발표를 “Meta가 드디어 최고 모델을 냈다”는 식으로 읽으면 핵심을 놓치기 쉽습니다. 공개 자료 기준으로는 Muse Spark를 새로운 SOTA라고 단정하기보다, Meta가 AI 모델 경쟁을 효율성, reasoning 실행 구조, 제품 통합 중심으로 재정렬하려는 신호로 보는 편이 더 정확합니다.
AI 모델은 앞으로도 계속 커질 것입니다. 하지만 모든 기업과 서비스가 항상 가장 큰 모델을 쓸 수는 없습니다. 실제 서비스에서는 비용, 응답 속도, 토큰 사용량, 배포 속도, 개인정보 처리, 안전성 문서가 함께 중요해집니다.
그래서 앞으로 AI 모델 발표를 볼 때는 질문을 바꿔야 합니다. “이 모델이 몇 점인가?”보다 “이 성능을 어떤 비용으로, 어떤 지연 시간 안에, 어떤 제품 경험으로 제공할 수 있는가?”가 더 실무적인 질문입니다.
Muse Spark의 의미는 바로 여기에 있습니다. 모델 경쟁의 다음 기준은 파라미터 수 하나가 아니라, 효율적으로 생각하고 빠르게 배포되며 사용자 맥락 안에서 작동하는 능력입니다.
FAQ
Q. Muse Spark는 언제 발표됐나요?
Meta는 2026년 4월 8일 Muse Spark를 발표했습니다. 공개 자료 기준 Muse 계열의 첫 모델로 설명됐습니다.
Q. Muse Spark는 현재 오픈소스인가요?
공개 자료 기준 현재 Muse Spark의 open-weight 모델이나 구체적인 오픈소스 라이선스 공개는 확인되지 않았습니다. 일부 파트너 대상 private API preview와 향후 오픈소스 가능성이 언급된 상태로 보는 것이 안전합니다.
Q. Muse Spark가 Llama 4 Maverick보다 무조건 좋은 모델인가요?
그렇게 단정하기는 어렵습니다. Meta는 같은 수준의 capability에 필요한 학습 연산량을 크게 줄였다고 설명했지만, 이는 자체 평가 기준을 바탕으로 한 주장입니다. 실제 사용 목적과 외부 평가를 함께 봐야 합니다.
Q. reasoning token은 쉽게 말해 무엇인가요?
모델이 답을 내기 위해 내부적으로 쓰는 생각의 양에 가깝습니다. 더 오래 생각하면 어려운 문제를 잘 풀 수 있지만, 비용과 응답 시간이 늘어날 수 있습니다. 그래서 같은 품질의 답을 더 적은 토큰으로 만드는 능력이 중요해지고 있습니다.
Q. 이 발표에서 일반 독자가 얻을 수 있는 핵심 인사이트는 무엇인가요?
AI 모델 경쟁은 더 이상 성능표만의 경쟁이 아니라는 점입니다. 앞으로는 성능, 비용, 속도, 제품 통합, 데이터 활용 방식까지 함께 봐야 AI 산업 흐름을 더 정확히 이해할 수 있습니다.